C++ 11相关新特性¶
约 8736 个字 1288 行代码 10 张图片 预计阅读时间 45 分钟
原始字符串¶
在前面使用字符串时,涉及到一些特殊字符,例如双引号",直接写在字符串中可能会导致编译错误,例如下面的代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 | |
\" C++11中为了解决减少在不需要使用转义字符的地方减少转义字符的使用引入了原始字符串,这种字符串允许所有字符以原样显示而不会被转义或者被作为特殊符号(例如引号被视为包裹字符串)
C++11原始字符串的使用R"(+)"包裹需要的字符串,规则如下:
| C++ | |
|---|---|
1 | |
使用原始字符串修改前面的代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
R"(+)"有个问题,那就是如果被包裹的字符串恰好想同时使用)",此时就会导致原始字符串提前遇到结束符,并且有一个)"落单,为了解决这个问题,还可以使用R"+*(+)+*"包裹其中有)"出现的字符串,例如下面的代码: | C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
Note
需要注意,不要交错使用R"(+)"与R"+*(+)+*"
列表初始化¶
初始化简单变量¶
在C语言和C++98中,对一中类型的变量进行初始化时,主要使用赋值符号与初始化值,如果是一个数组或者结构体等具有多个成员的变量初始化时,可以使用{}进行初始化,列表初始化如果内部没有内容,则变量初始化时值默认为0
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
上面的代码中需要注意对于一个数组和结构来说,为了兼容C语言,默认是使用{}进行初始化,此时不算作列表初始化,但是如果省略了赋值符号,也算作列表初始化,例如下面的代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
在C++11中,可以使用{}对所有类型的变量进行初始化,并且可以省略赋值符号
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
需要注意,如果使用了列表初始化,则不可以出现部分用于初始化的值赋值给变量后出现数据丢失的情况,例如double的值赋值给int的变量
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
初始化容器¶
有了列表初始化后,容器的初始化可以变得更加简单,对比下面的初始化方式
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
对于map来说,对比下面的初始化方式
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
在上面的代码中,对于C++ 98的初始化来说,通过多参数构造的隐式类型转换作为参数传递给insert()函数,而C++ 11中,结合了类型转换已经列表初始化对map进行初始化
列表初始化有以下几点好处:
- 方便,基本上可以替代普通括号初始化
- 可以使用初始化列表接受任意长度
- 可以防止类型窄化(narrowing conversion),避免精度丢失的隐式类型转换
decltype关键字¶
前面声明变量时使用auto关键字,根据赋值符号右侧类型推导变量的类型,但是如果没有赋值,auto此时不可以进行推导;为了知道某一个变量的类型,可以使用typeid(变量).name()进行获取,直接打印即可查看指定变量的类型
但是上面两种方式都无法做到根据已有变量/常量的类型创建新的变量,为了解决这个问题,在C++ 11中新增了decltype关键字
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
尾置返回值类型¶
在C++ 98中,函数的定义主要结构如下:
| C++ | |
|---|---|
1 2 3 4 | |
int (*)[10]时,上面的写法就会不便于阅读: | C++ | |
|---|---|
1 2 3 4 5 6 | |
而在C++ 11中,为了更好的可读性,可以使用->结合对应的函数返回值放置于形参列表后方,而在原来的函数名前方需要使用auto,所以下面的代码可以修改为:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
也可以结合decltype关键字,如下:
| C++ | |
|---|---|
1 2 3 4 5 | |
using与typedef¶
using和typedef都可以用来为已有的类型定义一个新的名称。
二者最主要的区别在于,using可以用来定义模板别名,using还可以引入命名空间,而typedef不能
-
typedef主要用于给类型定义别名,但是它不能用于模板别名。C++ 1 2
typedef unsigned long ulong; typedef int (*FuncPtr)(double); -
using可以取代typedef的功能,语法相对简洁。C++ 1 2
using ulong = unsigned long; using FuncPtr = int (*)(double); -
对于模板别名,
using显得非常强大且直观。C++ 1 2
template<typename T> using Vec = std::vector<T>; -
作用范围:
using还可以用于命名空间引入,typedef没有此功能。C++ 1 2 3 4 5 6 7
namespace LongNamespaceName { int value; } // using namespace LongNamespaceName; 直接引入命名空间 using LNN = LongNamespaceName;// 引入命名空间并为命名空间取别名 LNN::value = 42; // 相当于 LongNamespaceName::value
总之,更推荐使用using,尤其是当你处理模板时。在现代 C++ 代码规范中,C++11 之后,许多代码规范建议优先使用using而不是typedef。这证明了在实际应用和代码维护中,using更具有优势。
C++ 11新增的容器¶
下面红色标记的容器均为C++11新增的容器
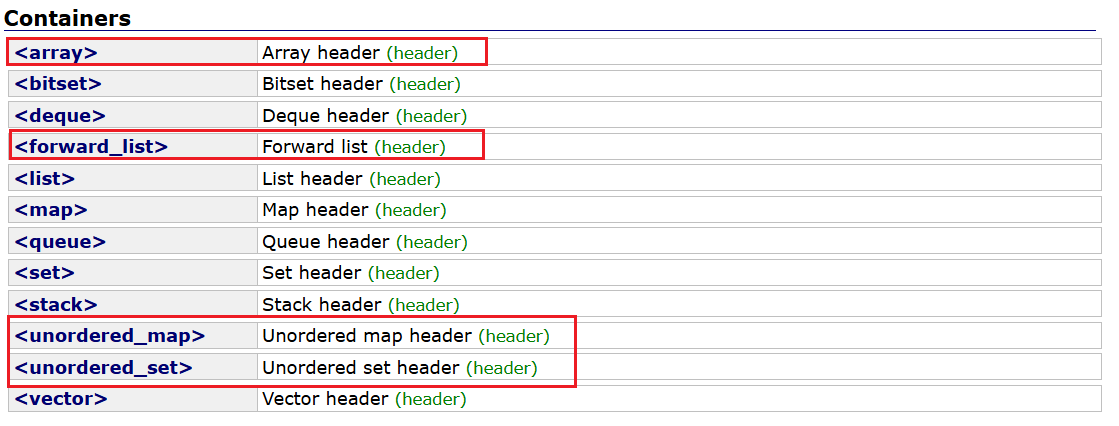
<array>:封装的是C语言静态数组,本质还是普通数组,只是为了便于控制数组越界等问题,因为一般的数组越界读写在编译阶段是不容易检测出来的
<forward_list>:单链表,这个单链表没有尾插和尾删,因为开销大
<unordered_map>和<unordered_set>:封装的是哈希表
左值引用和右值引用¶
左值与右值¶
左值代表赋值符号左侧的值,可以直接取地址,一般为变量,并且一般情况下可以修改(被const修饰的左值不可以修改)
右值代表赋值符号右侧的值,不可以直接取地址,一般为内置类型常量、函数返回值和表达式的值
右值不可以出现在赋值符号的左侧,否则会报错为不可修改的左值,但是左值可以出现在右侧,此时是将左值中的值赋值给赋值符号左侧的新左值,例如int b = 0; a = b;
右值可以分为两种
- 纯右值:一般为内置类型常量
- 将亡值:一般为函数返回值中的临时对象、匿名对象等即将被销毁的值
左值引用与右值引用¶
左值引用:即为对左值的引用,在类型后加一个&即可代表左值引用类型,例如int num = 0; int& ref = num; 中ref为左值num的别名,表达式int& ref = num;中的ref和num均为左值
右值引用:即为对右值的别名,在类型后加两个&即可代表右值引用类型,例如int&& ref = 1;,表达式中的ref为对右值引用的左值,1为右值
Note
一般情况下,左值引用的对象不可以是常量,因为临时变量具有常性,为了解决这个问题,可以使用const修饰左值引用,例如const int& num = 1;
左值引用和右值引用的相互转化¶
左值引用可以通过强制转换转化为右值引用,也可以通过move()函数进行变换,例如下面的代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
右值引用可以通过强制转换转化成左值引用,例如下面的代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
之所以可以通过强制转换实现左值引用和右值引用之间的相互转换是因为左值引用和右值引用在底层实际上都是一样的,只是语法层面对二者进行了更严格的定义,只要基本类型相同就可以通过强制转换进行改变,参考下图的汇编代码:

右值引用的使用¶
以模拟实现的string为例
模拟实现string代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 | |
拷贝构造函数与移动构造函数¶
在前面对于需要深拷贝的类来说,需要自己写类的拷贝构造函数,在没有移动构造函数时,只要是涉及到对象的拷贝都会调用拷贝构造函数,包括但不限于返回临时对象,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
上面的代码中模拟实现了to_string函数,函数返回一个simulate_string::string类的对象str,调用该函数:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
在编译器没有优化并且只有一个拷贝构造函数时,当执行main函数中的第一条语句时,执行过程如下:
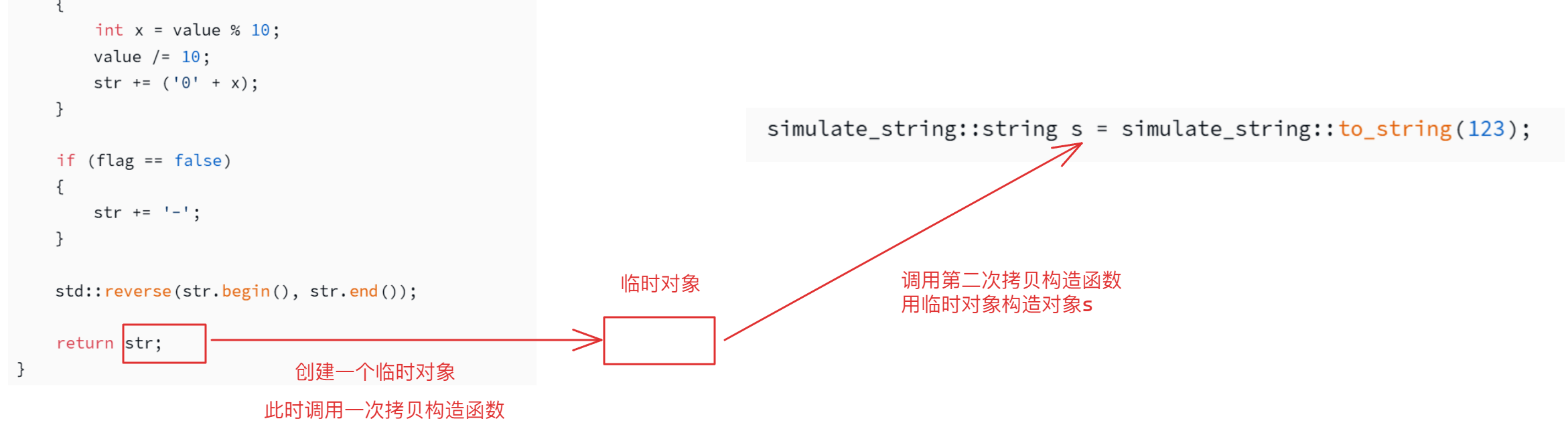
当编译器检测到当前写法simulate_string::string s = simulate_string::to_string(123);时,会进行优化,所以执行过程优化为直接调用拷贝构造函数构造对象s,如下图所示:
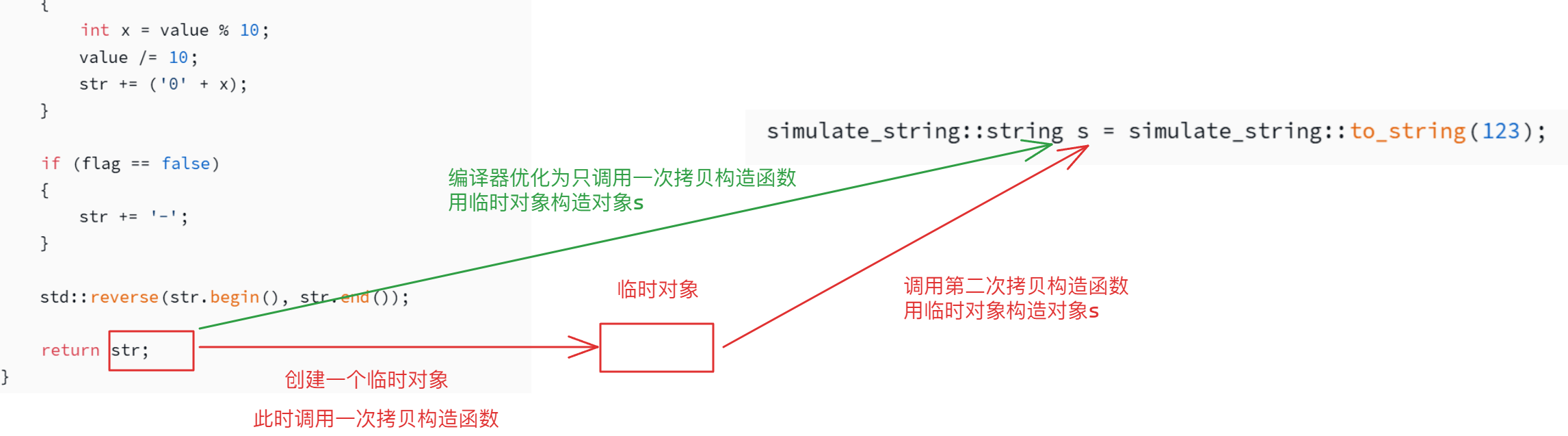
但是,进入拷贝构造函数中拷贝str的内容会存在一定的空间和时间消耗,所以为了解决这个问题,可以采用移动拷贝构造,移动拷贝构造本质就是利用了右值引用。str返回时,在未被编译器优化的情况下会生成一个临时对象,这个临时对象会进行一次拷贝,但因为临时对象是属于将亡值,所以使用右值引用的移动构造会更加方便且高效,只需要将临时对象中的值和现有对象中的值进行交换即可,移动构造如下:
| C++ | |
|---|---|
1 2 3 4 5 | |
有了移动构造函数以后,对于需要使用返回的临时对象进行拷贝构造时就会直接走移动构造,从而减少原来拷贝构造的消耗
Note
需要注意的是,为了确保可以交换成功形式参数不可以使用const修饰
在C++ 11中,构造函数也包括了移动构造,例如string类中的移动构造:

赋值重载函数与移动赋值重载函数¶
上面的移动构造只解决了在拷贝临时对象时会调用拷贝构造函数产生的消耗问题,如果main函数的代码修改为如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 | |
此时移动构造就无法解决问题,因为是赋值符号重载函数与临时对象之间的关系,同样,当编译器未进行优化时会进行下面的过程:
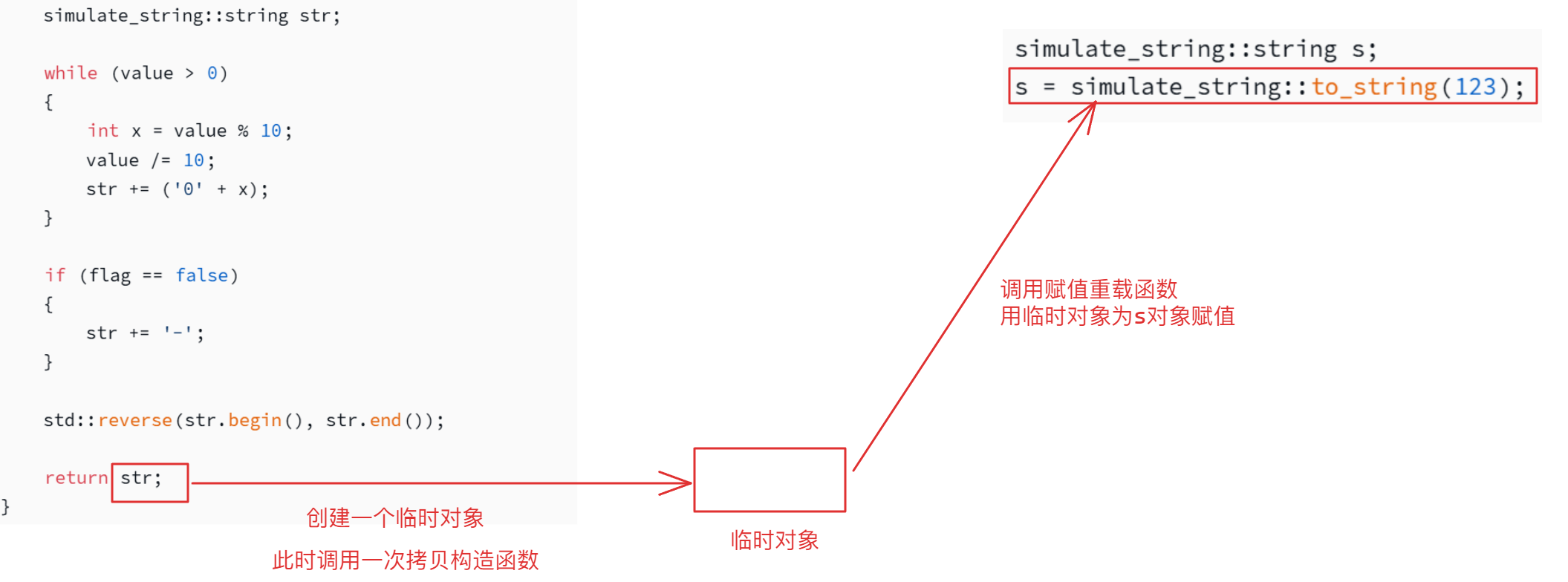
当编译器优化后,会直接调用一次赋值重载函数,用str对象为s对象赋值
但是尽管编译器进行了优化,赋值重载函数因为是将str中的内容深拷贝给s对象,所以依旧会产生开销,当对象很大时,开销也会变得很大。因为str是将亡值,所以可以采用右值引用的方式,重载一个新的赋值重载函数如下,同样只需要交换一下将亡值和当前对象中的内容即可:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 | |
在C++ 11中,赋值重载函数也包括了移动赋值重载函数,例如string类中的移动赋值重载函数:

元素插入相关函数¶
以模拟实现的list类为例
模拟实现list代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 | |
当在main函数中创建对象后进行尾插:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 | |
因为"1111"属于常量字符串,属于右值,在push_back函数中会调用Node节点的构造函数初始化_data,而因为_data是simulate_string类型的,所以会调用对应的构造函数将其转化为simulate_string类型,接着再链接,但是整个过程会涉及到simulate_string类的拷贝构造函数,并且因为_data是左值,所以在进入simulate_string类后也是左值,就不会调用前面的移动拷贝构造函数,这个现象也称为右值退化为左值,为了解决这个问题,首先需要修改push_back函数,将"11111"识别为右值,所以需要使用右值引用作为push_back函数的形式参数,所以push_back函数需要重载一份为如下形式:
| C++ | |
|---|---|
1 2 3 4 | |
接着,因为push_back底层调用的还是insert函数,所以insert函数的形式参数也需要重载一份为如下形式:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
但是,仅仅修改这两个函数的形式参数并不能解决问题,首先看push_back函数,因为底层调用的是insert函数,所以需要将push_back的右值引用x接收到的值继续传递给insert函数,此时需要注意,右值引用本身还是左值,所以传递给insert函数参数的x依旧还是左值,此时尽管写了重载右值引用的insert函数,依旧会调用左值引用的insert函数,所以需要对push_back函数进行进一步的修改,如下形式:
| C++ | |
|---|---|
1 2 3 4 | |
接着到insert函数,在push_back函数修改为上述形式后,此时调用的insert函数即为重载右值引用的版本,接下来创建节点,此时依旧是同样的问题,x是右值引用,但是本身是左值,所以传递给Node节点的构造函数时也依旧是左值,所以同样需要将其转化为右值,如下形式:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
接着是Node节点的构造函数,当前情况下只有一个左值引用版本的构造函数,所以需要重载一个右值引用版本,如下形式:
| C++ | |
|---|---|
1 2 3 4 5 | |
但是上面的代码依旧是同样的问题,形式参数data是右值引用,但本身是左值,所以需要将data转化为右值,修改为:
| C++ | |
|---|---|
1 2 3 4 5 | |
此时再调用simulate_string类的构造函数时,就会只调用移动拷贝构造函数
在C++ 11中,元素插入相关的函数也包括了右值引用的版本,例如list类中的右值引用版本的push_back函数:

万能引用与完美转发¶
万能引用¶
万能引用可以将在函数模版中使用,形式如下:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
在上面的代码中,T&&是一个万能引用,当传递左值时,T被推导为左值引用,当传递右值时,T被推导为右值引用,但是不论T被推导为左值引用还是右值引用,形参t本身依旧是左值,所以当需要再向下传递需要使用到右值时,依旧需要将t进行转化,例如下面的例子:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
此时不论t是左值引用还是右值引用,t本身都是左值,所以传递给Func函数只会走打印“左值引用”的部分,如果使用move对形参t进行转化,那么只会走打印“右值引用”的Func函数,为了解决这个问题,可以使用完美转发
完美转发¶
完美转发可以将变量原有的类型传递给下一层,如果本身是左值引用,则完美转发后就是左值引用,如果本身是右值引用,则完美转发后就是右值引用,所以上面的代码可以写成:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
有了完美转发后,就可以对上面list模拟实现中的插入函数进行修改,前面遇到的问题就是本身是右值,给了右值引用再向下传递时发生右值引用退化为左值引用,所以可以使用完美转发使其按照右值引用的方式传递,以push_back为例
| C++ | |
|---|---|
1 2 3 4 | |
C++ 11新增的两个默认成员函数¶
在有了移动拷贝构造函数和移动赋值重载函数后,类的默认成员函数从原有的6个变为了现在的8个,对于新增的两个默认成员函数来说,默认的生成规则如下:
- 移动拷贝构造函数:当类中没有显式写移动拷贝构造函数并且类中也没有显式写拷贝构造函数、析构函数和赋值重载函数时,编译器会默认生成移动拷贝构造函数,该函数的行为是,当类中的成员是内置类型时,将会进行值拷贝,当类中的成员是自定义类型时,会调用自定义类型的移动拷贝构造函数,如果自定义类型也没有移动拷贝构造函数,则调用拷贝构造函数
- 移动赋值重载函数:当类中没有显式写移动赋值重载函数并且类中也没有显式写拷贝构造函数、析构函数和赋值重载函数时,编译器会默认生成移动赋值重载函数,该函数的行为是,当类中的成员是内置类型时,将会进行值拷贝,当类中的成员是自定义类型时,会调用自定义类型的移动赋值重载函数,如果自定义类型也没有移动赋值重载函数,则调用赋值重载函数
Note
理解满足两个条件(1. 没有显式写移动拷贝构造函数 2. 没有显式写拷贝构造函数、析构函数和赋值重载函数):
考虑移动赋值重载函数和移动拷贝构造函数的使用场景:当类中的成员都是内置类型时,没有大型资源释放行为,所以不需要显示写析构函数,此时对于拷贝构造函数和赋值重载函数来说,直接复制原有对象的内容开销也不大,而对于移动拷贝构造函数和移动赋值重载函数来说,目的就是解决拷贝构造函数和赋值重载函数在部分场景下的时间和空间消耗,所以没有拷贝构造函数、析构函数和赋值重载函数代表没有大型的资源释放行为,自然也就可以不会产生大量的时间和空间消耗,所以也就不需要写移动拷贝构造函数和移动赋值重载函数
生成默认成员函数=default¶
如果一定要生成默认的移动拷贝构造和移动赋值重载函数时,可以使用=default关键字,例如如果需要默认生成string类的拷贝构造函数,可以写成:
| C++ | |
|---|---|
1 | |
Note
需要注意的是,如果想让编译器默认生成移动拷贝构造函数和移动赋值重载函数时,一定要有拷贝构造函数、析构函数和赋值重载函数的出现,哪怕是使用=default让移动拷贝构造函数和移动赋值重载函数默认生成,不可以缺少三个默认成员函数的一个,否则无法通过编译
不生成默认成员函数=delete¶
如果不想编译器默认生成某一个默认成员函数时,可以使用=delete关键字,例如如果不像默认生成string类的拷贝构造函数,可以写成:
| C++ | |
|---|---|
1 | |
在C++ 98中,如果不想一个对象可以通过调用拷贝构造函数和赋值重载函数进行构造可以将对应的拷贝构造函数和赋值重载函数修饰为private,而在有了C++ 11的=delete关键字后,就可以对这两个函数修饰为=delete,而无需在放入private中
C++ 11中的可变参数模版¶
可变参数模版介绍¶
在C++ 98中,如果一个函数是一个模版函数,那么该函数可以传递的参数个数就由模版参数个数决定,如果传递参数多于或少于(此处不考虑含有缺省参数的情况)规定的模版个数,则编译器无法生成对应的函数
在C++ 11中,为了解决上面的问题提出了可变参数的函数模版,基本格式如下:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
在上面的代码中使用...代表可变参数,...Args代表模版参数包,... args代表形式参数包,参数包中可以有[0, N] (N >= 0且N为整数)个模版参数,此时编译器会根据传递的参数个数生成对应的函数。
如果想要获取函数参数的数量时,可以使用sizeof运算符计算形式参数包,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
Note
sizeof计算属于编译时就可以计算的,所以可以直接使用,需要注意省略号的所在位置
如果想在函数func中查看传递的参数时则不可以使用遍历等运行时的逻辑进行打印,例如使用for循环
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
参数包展开¶
为了能够展示参数,下面采用两种方法进行显示,以下面的代码为例:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
-
编译时递归展开参数包
编译时递归和运行时递归的最大区别就是不可以使用
if语句进行递归结束条件的判断编译时递归展开参数包的思路是:创建一个有可变参数模版的函数
func,该模版参数含有两部分,第一个部分是万能引用的单一参数,该部分用于接收每一个参数值,第二个部分是可变参数模版,在函数体内,先打印第一个参数的内容,再调用func函数,传递剩余的参数,用于递归调用,再外侧写一个无参的func函数,该函数作为编译时递归的终止条件C++ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// 递归终止函数 void func() { cout << endl; } template<class T, class... Args> void func(T&& x, Args... args) { // 打印当前的x cout << x << " "; // 递归调用打印剩余的参数 func(forward<Args>(args)...); } 对于上面的测试函数,结果如下: 1 2 3 1 hello 3.14以第二个测试为例
func(1, 2, 3);,上面的代码可以理解为:C++ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
//4. 第四步 void func() { cout << endl; } //3. 第三步 void func(int&& z) { cout << z << " "; func(); } //2. 第二步 void func(int&& y, int&& z) { cout << y << " "; func(forward<int>(z)); } //1. 第一步 void func(int&& x, int&& y, int&& z) { // 打印当前的x cout << x << " "; // 递归调用打印剩余的参数 func(forward<int>(y), forward<int>(z)); } -
利用数组根据个数初始化数组大小的机制展开参数包
该方式的原理是:当一个数组在初始化时,如果不指定数组的大小,编译器会根据数组的元素个数推导出数组的大小,所以可以写为:
C++ 1 2 3 4 5 6
template <class... Args> void func(Args&&... args) { int arr[] = { ((cout << forward<Args>(args) << " ", 0))... }; cout << endl; }Note
这个方法需要注意,对于没有实参的函数来说会编译报错,例如
func()函数,并且不可以去掉逗号表达式,因为cout的返回值是ostream类型,该类型不支持赋值运算符重载函数上面的方法可以理解为:
C++ 1 2 3 4 5 6
// 上面的展开可以理解为 void func(int&& x, int&& y, int&& z) { int arr[] = { ((cout << forward<int>(x) << " ", 0)), ((cout << forward<int>(y) << " ", 0)), ((cout << forward<int>(z) << " ", 0)) }; cout << endl; }因为数组在开辟大小是会计算元素的个数,逗号表达式的左右两侧都会进行运算,所以先打印
x的值,再执行0,所以第一个表达式的值为0,作为数组的第一个元素,以此类推直到最后一个元素
可变参数模版的应用emplace系列函数¶
在前面学习到的容器中,基本上都支持emplace系列的函数,以list类为例,list类中存在一个emplace_back函数,该函数可以支持在list的尾部插入数据,与push_back函数实现的功能基本一致,但是emplace_back函数除了可以支持插入已经构造的对象和单个用于构造对象的值,还可以接受构造函数的参数,直接在list的内存空间中调用该对象的构造函数,避免了额外的拷贝或移动操作。这可以提高效率,尤其是在处理复杂杂对象时,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
之所以可以接受构造函数的参数,是因为emplace_back函数本身是一个可变模版参数的函数模版,但是注意,这个可变参数模版不代表可以传递多个参数,例如,插入多个字符串ls.emplace_back("1111", "2222");这种行为是错误的
使用可变参数模版模拟实现emplace_back函数,以模拟实现list为例:
因为emplace_back本身是一个插入函数,所以底层调用insert函数即可,将函数的形式参数设置为右值引用,为了可以实现向下传递时也是右值引用,需要使用完美转发,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
接着,实现insert函数针对emplace_back的版本,因为需要调用构造函数,所以当是右值引用时,需要保留是右值引用,同样需要使用完美转发
| C++ | |
|---|---|
1 2 3 4 5 6 7 | |
最后,完善Node节点的构造函数,使其满足可变参数模版,同样需要完美转发
| C++ | |
|---|---|
1 2 3 4 5 6 | |
emplace系列函数和push系列函数的选择¶
以vector中的emplace_back和push_back为例
push_back 和 emplace_back 都是 vector 类的成员函数,用于在 vector 的末尾添加元素。它们之间的主要区别在于添加元素的方式:
push_back:接受一个已存在的对象作为参数,进行拷贝或移动,将其添加到 vector 的未尾。这会引发一次拷贝或移动构造函数的调用,具体取决于传递的对象是否可移动。emplace_back:接受构造函数的参数,直接在 vector 的内存空间中调用该对象的构造函数,避免了额外的拷贝或移动操作。这可以提高效率,尤其是在处理复杂对象时。
使用场景:
- 如果需要将一个已经存在的对象添加到vector中,使用
push_back - 如果希望直接在vector中构造对象,避免额外的拷贝或移动开销,使用
emplace_back
Note
当然可以无脑选择emplace_back函数
lambda表达式¶
引入¶
在C++ 98中,对于sort函数来说,如果需要根据不同的比较方式实现不同的排序结果,需要写不同的仿函数,而在C++ 11中,可以通过lambda表达式解决这个问题,例如下面的例子:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
当需要按照商品的价格和评价排序时,则需要写两个仿函数
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
调用时传递仿函数匿名对象
| C++ | |
|---|---|
1 2 | |
但是当需要按照其他方式进行比较时,需要再写其他的仿函数,为了简化步骤,可以使用lambda表达式
lambda表达式介绍¶
lambda表达式基本结构如下:
| C++ | |
|---|---|
1 2 3 4 | |
- 捕捉列表:编译器根据
[]来判断接下来的代码是否为lambda函数,用于传递在lambda表达式体内的使用到的参数,一般为lambda表达式所在的直接作用域的变量 - 形式参数:用于lambda表达式体内的变量,如果不需要传递形式参数,则当前项可以省略不写,如果需要加
mutable,则不论是有还是没有形式参数,都需要带上() mutable:默认情况下lambda表达式捕捉列表的参数是被const修饰的,所以捕捉列表的参数是以传值的方式传递时是无法直接在lambda表达式内部进行修改的,但是如果加了mutable,就可以取消const属性->返回值类型:与普通的函数体一样的返回类型声明,但是此处一定要使用尾置返回值类型,如果lambda表达式的返回值类型比较明确时,该项可以不写- 函数体:同普通函数
Note
mutable关键字在C++中也可以在一个const结构体中修饰一个变量,此时被mutable修饰的变量就是const结构体中可以修改的变量,而其他的没被mutable变量则不可以
有了lambda表达式,引入部分的例子中的仿函数可以用lambda表达式进行替换,如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
lambda表达式捕捉列表的传递形式¶
如果没有形式参数传递,lambda表达式想使用其所在的直接作用域中的变量(全局除外)需要在捕捉列表中传递,在lambda表达式中,捕捉列表的传递形式一共有4种:
- 具体变量值传递
[variable]:直接传递变量的值,在lambda表达式中就是对该变量的值进行拷贝,所以lambda表达式内部对variable修改时不影响variable本身的内容,并且在没有mutable的情况下不可以在内部对variable进行修改 - 具体变量引用传递
[&variable]:以variable引用的方式传递,在lambda表达式中可以对variable内容进行修改,从而达到传址调用的效果 - 所有变量值传递
[=]:将lambda表达式所在作用域中的变量全部以传值的方式传递给lambda表达式,具体传递了哪些值需要看lambda表达式中使用到了哪些值 - 所有变量引用传递
[&]:将将lambda表达式所在作用域中的变量全部以传址的方式传递给lambda表达式,具体传递了哪些值需要看lambda表达式中使用到了哪些值,如果lambda内部需要进行修改,需要加mutable
Note
对于第二种情况,如果想在lambda表达式内部修改lambda所在作用域的变量的值,可以在lambda表达式的形式参数部分以引用的方式传递实参,此时就可以不需要添加mutable关键字,这个方法与普通函数的思路一致
上面4种方法也可以交错使用,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
for_each函数与lambda表达式¶
for_each()是C++11中引入的一种容器遍历方式,其原型如下:
| C++ | |
|---|---|
1 2 | |
InputIterator,所以可以传递单向、双向和随机迭代器,第三个参数可以传递仿函数或者lambda表达式 第三个参数中一般是指定在循环遍历中对遍历容器元素的操作,例如遍历容器元素等
例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
lambda表达式的原理¶
前面通过lambda表达式简化了原本应该使用仿函数改写比较方式的例子展示了lambda表达式的使用,但是lambda表达式实际与仿函数的原理基本一致,所以lambda表达式也被称为匿名函数,观察下面的代码的反汇编代码
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
反汇编如下:

需要注意的是,lambda表达式对象不可以相互转化,尽管完全相同,在底层两个逻辑一模一样的lambda表达式存在不同的lambda+uuid名称
包装器¶
包装器的基本使用¶
C++11中引入了function包装器,也叫做适配器,在前面有了lambda表达式后,可以发现如果直接调用lambda表达式的对象,其方式和函数的调用基本相同,但是前面的函数还有可能是仿函数,为了使程序的模版使用效率变高,可以使用包装器
Note
使用包装器需要引入头文件<functional>
包装器可以根据已有的函数、函数指针、lambda表达式进行包装,基本结构如下:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
Note
需要注意,使用包装器必须保证包装器中的模版参数(返回值和形式参数)与被包装的对象完全相同
使用方式如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | |
上面代码中,包装普通函数与包装函数指针类似,包装成员函数需要注意两种形式:1. 静态成员函数 2. 非静态成员函数,对于静态成员函数来说,可以直接取地址,与普通函数类似,但是需要指定类域,而对于非静态成语函数来说,需要加上&,因为非静态成员函数存在一个隐含的参数this,需要依赖对象实例进行调用,所以非静态成员需要传递一个类名(或类指针)代表调用时需要传递同类类型的(匿名/非非匿名)对象(或对象地址),在调用包装后的函数时,实际上是通过对象进行调用,而不是包装器进行调用,对于lambda表达式来说,直接使包装器接受lambda表达式即可
包装器与重载函数¶
重载函数的根本条件就是必须满足函数名相同,但是此时如果直接使用函数名作为包装器的对象就会产生二义性问题,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
在上面的代码中,map的模版参数是int和function<int(int, int)>,代码中也存在对应包装器模版类型的add函数,但是编译器并不会自动选择对应的重载函数,所以在出现重载函数时,推荐使用函数指针对重载函数进行指代,再传入函数指针,避免传入重载函数的函数名,另外也可以使用lambda表达式,从而不使用函数重载,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
包装器的使用¶
C++形式的转移表,以实现简易计算器为例:
下面的代码是用于计算的函数:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
常规写法:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
使用包装器后:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
绑定¶
在C++ 11中,增加了绑定配合包装器的使用,包装器可以实现两种功能:
- 改变实参在传参时的顺序
- 固定形参中的某一个值
Note
使用bind时需要展开命名空间placeholders,因为要使用其中的_1,_2...
placeholders中的内容表示调用绑定函数的实际参数,_1代表第一个实际参数,_2代表第二个实际参数,以此类推
- 改变实参在传参时的顺序
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
传递顺序改变如下图所示:

Note
注意,bind改变的是实际参数的传递顺序,而不是形参的接收顺序,形参接收还是按照从左到右依次接收传递的实际参数,只是写的第一个实际参数(本应该传递给形参a)被bind改变作为第三个实际参数,传递给形参c,依次类推a和b
- 固定形参中的某一个值
在前面使用function包装器调用非静态成员函数时,需要单独传递一个对象给隐含的this指针,如果每一次传递都需要传递一个对象会显得繁琐,可以考虑将对象参数进行固定,例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
上面代码中,需要注意尽管固定了func2的第一个参数,实际参数的指代还是从_1开始,如果固定中间的参数,则最左边的为_1,最右边的为_2(代码如下),以此类推
| C++ | |
|---|---|
1 2 | |
需要注意的是,如果使用绑定固定一个参数传给指定的函数,这个参数是按照值传递的方式而不是引用,所以如果要用引用的方式,可以考虑使用ref函数,例如:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |