Linux进程控制¶
约 5805 个字 843 行代码 11 张图片 预计阅读时间 30 分钟
进程创建¶
在Linux进程基础篇已经提到过使用fork函数创建一个子进程。
回想使用fork函数时,其返回值当子进程创建失败时,父进程接收到-1;当子进程创建成功时,则对于子进程来说接收到的返回值为0,而父进程接收到的返回值为子进程的PID
其原因现在也可以解释:前面提到当子进程不修改与父进程共享的数据时,子进程和父进程拥有同一块数据空间,但是因为fork函数创建完子进程后,函数会对两个进程的同一块区域的数据进行修改,导致子进程拥有的是一块新的空间,并在新的空间中写入0,而父进程依旧对应原来的空间,并在原空间中写入子进程的PID
以上便是在代码中创建子进程的步骤
进程终止¶
前面在父进程中创建子进程只满足了创建,并没有满足终止。在程序中,如果想终止一个进程,可以使用三种方式:
main函数中return- 在代码任何位置使用
exit()函数,参数可以是任意整数 - 在代码任何位置使用
_exit()函数,参数可以是任意整数
Note
第二个方式和第三个方式与第一个方式最大的不同:第一个方式只会结束某一个函数,而第二个方式和第三个方式会直接结束一个进程
之前C语言部分介绍过:在不同的系统和C语言标准库的实现中都规定了一些错误码,一般是放在 errno.h 这个头文件中说明的,C语言程序启动的时候就会使用一个全局变量errno来记录程序的当前错误码,只不过程序启动的时候errno是0,一般0表示没有错误,而非0表示存在错误。当我们在使用标准库中的函数的时候发生了某种错误,就会将对应的错误码存放在errno中,而一个错误码的数字是整数很难理解是什么意思,所以每一个错误码都是有对应的错误信息的,但是不同的操作系统会存在不同的错误码和错误信息,为了更方便的显示指定的错误码对应的错误信息,可以使用strerror函数,参数传递errno变量或者指定的错误码。除了标准库中已经定义的错误,也可以约定某些错误码表示某种错误
不论是库或者系统已经提供的错误码,还是自定义的错误码都可以作为exit函数和_exit函数的参数传递
但是,exit函数和_exit函数存在细微的差别:exit函数在结束进程时,会刷新进程的缓冲区,但是_exit函数不会,例如下面的代码:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
因为exit函数是基于系统调用接口的函数,属于语言层面的函数,而_exit函数是系统的调用接口函数,前面提到\n可以刷新缓冲区,所以可以推断出,此处所谓的缓冲区实际上是语言级别的缓冲区。_exit函数在操作系统内部运行,并不知道有缓冲区的存在,自然也就无法刷新该缓冲区,对应的exit函数是语言层面的函数,对应的缓冲区是语言层的缓冲区,所以可以做到缓冲区刷新
Note
可以认为exit函数底层调用了_exit函数和fflush函数
在进程结束部分提到过,可以使用echo $?获取最近一次结束的进程的退出码,所以此处也可以获取到通过return、exit或者_exit结束的进程返回值,查看上面的代码进程的退出码如下:

进程回收¶
在前面创建子进程中,并没有提到如何回收子进程,一旦子进程在父进程结束之前结束,子进程便会一直处于僵尸状态等待父进程回收,如果一直不回收便一直处于僵尸状态导致内存泄漏。在Linux,如果需要父进程对子进程进行回收,避免持续僵尸可以使用下面的两种方式:
- 使用
wait()函数,该函数会等到任意子进程执行结束之后回收该子进程,再执行该函数后面的代码,参数传递一个用于接收子进程状态的状态变量地址,函数返回回收的子进程的PID - 使用
waitpid()函数,同wait函数,但是该函数可以指定接收的进程,第一个参数传递需要回收的子进程的PID,第二个参数传递用于回收的子进程状态的状态变量地址,第三个参数传递指定函数的行为,函数返回回收的子进程的PID。当回收失败时,返回-1,否则返回对应的pid
Note
如果waitpid函数第一个参数传递一个大于0的数(即子进程PID),则回收指定的进程,如果传递-1,则作用等同于wait函数
基本使用如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
为了更好得监视执行时子进程的变化,可以使用下面的Shell脚本每隔一秒进行一次监视:
| Bash | |
|---|---|
1 | |
编译运行上面的代码后,可以看到下面的效果:

使用waitpid函数可以修改为如下代码,效果同上面的代码:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
如果需要回收子进程的状态,可以通过状态变量接收,因为waitpid函数的第二个参数相当于一个输出型参数:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
如果上面子进程的退出码为非0,那么status中的值可能会有所不同,代码如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
运行上面的代码效果如下:
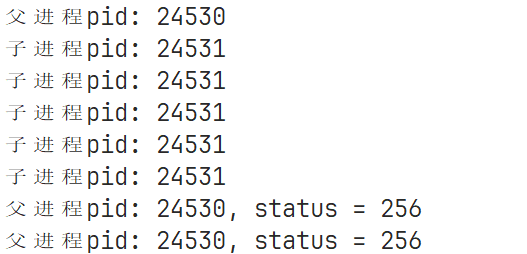
在上面的代码中,子进程的退出码是1,但是status中存储的却是256,因为在Linux中,一个进程退出一般不仅仅包含退出码,还有其他内容,这些内容统称为为进程退出信息。
进程退出信息¶
下面主要讨论两种进程退出信息:
- 进程退出码
- 进程退出信号
在Linux中,存在一个整型值status,该值存储了进程的相关退出信息,一般情况下,一个整型值占用4个字节,所以在status中,低两个字节(比特位从9到15)存储的就是进程退出码(占用8-15)和进程退出信号(占用0-7),示意图如下:
Note
第8位比特位存储的core dump标志,具体见Linux信号

所以在上面的代码中,进程退出码设置为1,实际上是在第9位比特位设置为1,即0000001,但是因为进程是正常退出的,所以进程信号部分为全0,core dump此时也为0,就出现了000000100000000,所以此时获取到的status就是256
如果想要直接获取进程退出码可以使用下面的思路:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
Note
上面的代码中,使用了(status>>8)&255取出进程退出码,注意尽管已经将 status 右移 8 位把高 8 位移到低 8 位的位置,但是为了保证其他位置为0,需要与255进行&运算
在Linux中,进程退出码一般即为0或者errno中的值,也可以是自定义的整数值,而进程退出信号中0表示正常退出,其他对应着不同的进程退出信号,如下图所示:

例如信号8和信号11:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
这些退出信号默认由操作系统检测并向进程发出,所以当用户看到进程退出信号时,其实操作系统在这之前已经终止了进程,这种进程退出也被称为进程异常退出。至此,在Linux中,进程退出一共有三种情况:
- 进程代码执行完成,进程退出码为0,进程退出信号为0,正常退出
- 进程代码执行完成,进程退出码为非0,进程退出信号为0,正常退出但是程序出现逻辑问题导致指定任务未完成
- 进程代码未执行完成,进程退出信号为非0,进程异常退出
对于子进程出现进程退出信号非0,也可以通过下面的方式获取对应的进程退出信号:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
除了操作系统可以向进程发送进程退出信号,用户也可以通过kill指令向进程发送对应的退出信号,使用方式与使用kill结束进程一致
上面获取进程退出信息的方式稍微有点繁琐,在Linux中,有对应的宏可以帮助获取到指定的进程退出信息:
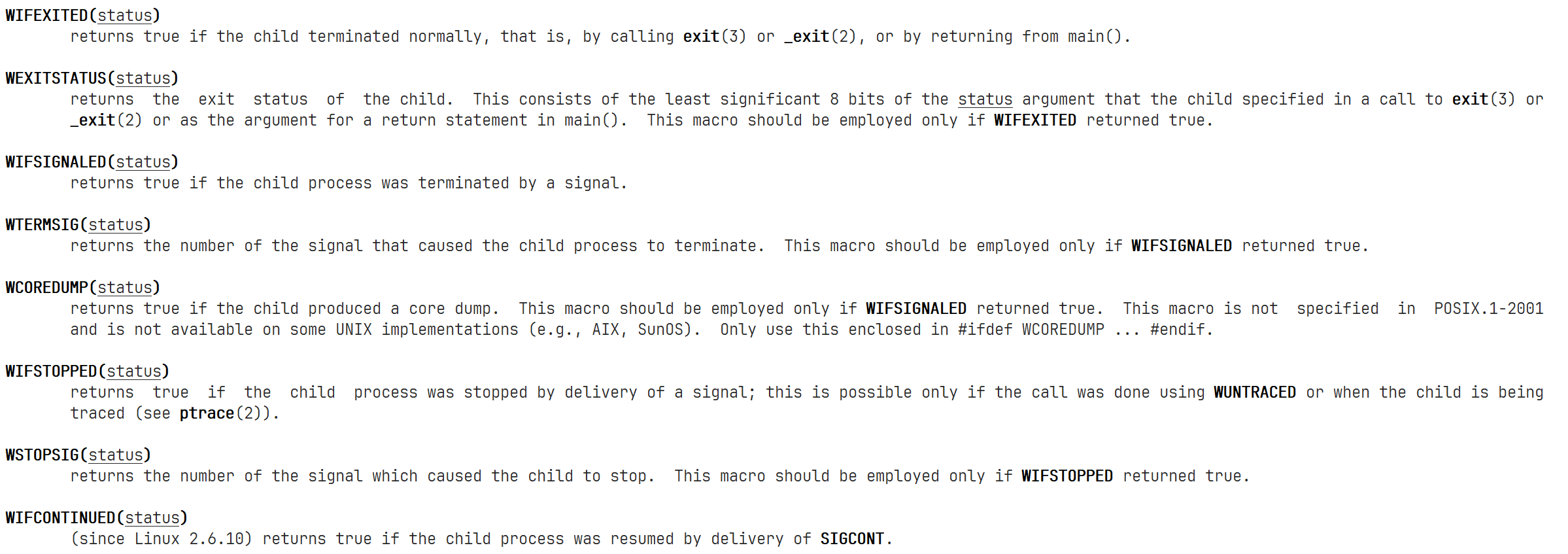
例如下面的代码:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
在Linux源码中,PCB中存在着两个变量分别存储着进程退出码和进程退出信号:
| C | |
|---|---|
1 2 3 4 5 | |
子进程使用案例¶
前面的子进程都只是完成一些简单的打印工作,现在可以通过子进程完成一些其他工作,实现子进程执行其他任务的效果:
目标:父进程向容器中添加数据,而子进程将数据保存到指定的文件中
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | |
阻塞与非阻塞¶
在上面的子进程案例中,每一次子进程在执行任务时,父进程都需要等待子进程执行完毕后回收子进程才可以继续执行父进程的代码,这个过程中父进程处于阻塞等待状态
但是如果希望父进程在子进程还在执行的时候一边等待子进程结束,一边执行自己的任务就需要让父进程处于非阻塞等待状态
需要使用非阻塞状态就需要设置waitpid第三个参数为WNOHANG,此时waitpid的返回值从原来的两种(大于0和等于-1)变为三种(大于0、等于0和等于-1),此时大于0表示已经回收到对应的子进程的PID,等于0说明子进程还在执行需要继续等待,等于-1说明回收失败
Note
因为非阻塞等待无法确定子进程何时退出,所以需要手动循环持续等待
使用非阻塞等待修改前面的案例代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |
进程程序替换¶
介绍¶
前面子进程在完成任务都是基于分支语句中属于子进程的代码,而进程程序替换的作用就是为了让子进程执行其他程序的代码和数据
在Linux中,有七个可以调用其他程序的函数(也被称为exec家族函数),如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
参数解释:
const char *path:执行的目标程序的路径const char *arg, ...:如何执行目标程序,一般传入的内容与命令行执行对应程序时输入的内容相同,例如ls -a -l,参数写为"ls", "-a", "-l", "nullptr/NULL"(需要传入nullptr或者NULL是因为命令行参数表以nullptr/NULL结尾)char *const argv[]:如何执行目标程序,与const char *arg, ...不同的是,char *const argv[]接收的是一个数组,所以需要额外创建一个数组,而数组中的内容即为命令行参数,以nullptr或者NULL作为最后一个字符串const char *file或者const char *filename:执行的目标程序名称(不需要路径)char * const envp[]:需要传递的环境变量,与char *const argv[]使用基本一致,一般有新的环境变量时才会使用本参数
函数返回值解释:
上面所有的函数当正常调用程序时,返回-1,否则没有返回值

下面以三种函数为例:
共用的Makefile文件如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
-
int execl(const char *path, const char *arg, ...)C 1 2 3 4 5 6 7 8 9
#include <stdio.h> #include <unistd.h> int main() { execl("/usr/bin/ls", "ls", "--color", "-a", "-l", NULL); return 0; }运行结果:
-
int execvp(const char *file, char *const argv[])C 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#include <stdio.h> #include <unistd.h> int main() { char* const argv[] = { (char*) "ls", (char*) "--color", (char*) "-a", (char*) "-l", NULL }; execvp("ls", argv); return 0; }运行结果:
Note
上面的代码中,使用
(char*)是为了将字符串的类型(const char*)强制转换为char*,从而类型匹配以消除编译器警告也可以使用下面的更安全的方式:
C 1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include <stdio.h> #include <unistd.h> int main() { char cmd[] = "ls"; char opt1[] = "--color"; char opt2[] = "-a"; char opt3[] = "-l"; char* const argv[] = { cmd, opt1, opt2, opt3, NULL }; execvp("ls", argv); return 0; } -
int execvpe(const char *file, char *const argv[], char *const envp[])C 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include <stdio.h> #include <unistd.h> int main() { char cmd[] = "ls"; char opt1[] = "--color"; char opt2[] = "-a"; char opt3[] = "-l"; char* const argv[] = { cmd, opt1, opt2, opt3, NULL }; char newEnv[] = "newEnviron=10000"; char* const envp[] = {newEnv, NULL}; execvpe("ls", argv, envp); return 0; }运行结果:
如果需要添加环境变量到当前系统的环境变量并以新的系统环境变量执行,可以使用下面的代码:
C 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
#include <stdio.h> #include <unistd.h> #include <stdlib.h> extern char** environ; int main() { char cmd[] = "ls"; char opt1[] = "--color"; char opt2[] = "-a"; char opt3[] = "-l"; char* const argv[] = { cmd, opt1, opt2, opt3, NULL }; char newEnv[] = "newEnviron=10000"; putenv(newEnv); execvpe("ls", argv, environ); return 0; }Note
此处
char**和char* []是兼容的类型,都表示一个指向字符串指针的指针数组,所以可以将char** environ传递给char* const envp[]参数,因为两者在内存布局上是相同的
原理简单解释¶
进程程序替换的本质是将进程对应的虚拟地址空间中的代码和数据替换为指定的程序的代码和数据,从而可以执行其他程序,示意图如下:
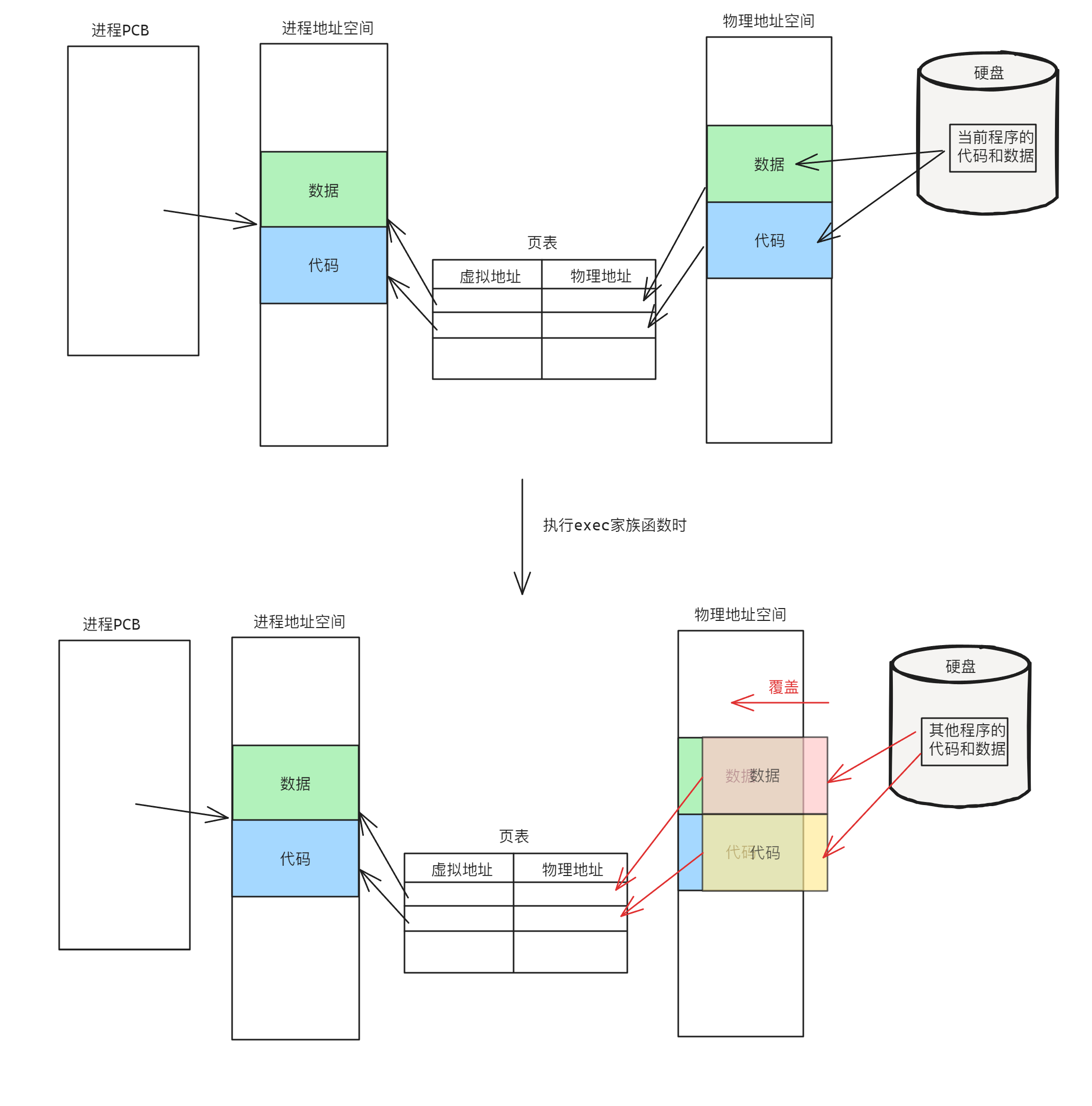
因为发生了覆盖,所以一旦执行了exec家族的函数,则该函数后面的代码都会被覆盖从而无法再执行,除非exec家族函数执行失败返回-1
但是需要注意的是,因为是直接覆盖,所以这个过程中exec函数并不会创建一个新进程,运行下面的代码可以证明(只要PID相同,就说明不是新进程执行的exec函数中的程序):
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Note
需要注意,上面的execl第二个参数不用使用./other,此处只需要使用other即可,因为已经指定了路径
前面提到大部分运行在bash上的进程都是bash子进程,所以bash执行子进程的本质就是调用了exec家族函数,而之所以没有覆盖bash原有的进程,就是因为bash开辟了一个子进程再在子进程中调用了exec家族函数。所以可以模仿bash的方式使用多进程,让子进程执行exec家族函数:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
有了进程程序替换,进程的独立性更加明显,原因如下:
- 完全替换进程映像:当一个进程调用
exec系列函数时,它的当前进程映像被新程序替换,除了进程PID和一些资源之外,原进程的代码、数据和堆栈都被新程序的内容替换。这意味着新程序完全独立于调用exec之前的程序 - 资源独立性:尽管新程序继承了原进程的文件描述符和环境变量,但它使用的是自己的代码和数据,这使得程序的执行和行为是独立的,不会受到原程序的影响
- 内存空间独立:
exec调用后,新程序运行在独立的内存空间中,之前的内存内容被清除,新程序的运行不受之前程序的内存内容的影响 - 进程控制:调用
exec后,原进程的执行流被终止,新程序开始执行。控制权完全交给新程序,使得新程序在执行和资源管理上是独立的
手撕一个简单的shell(版本1)¶
在写一个shell之前,需要了解本次实现的shell在系统中做的事情:
- 从硬盘中读取环境变量存储到自己的环境变量表(本次以拷贝系统shell的环境变量到模拟实现程序中为例)
- 当在shell运行的过程中,如果用户输入一个指令且该指令可以对应到一个程序,则该程序会正常运行
根据上面的描述以及系统shell的直观感受,可以将本次模拟的shell需要做的内容分为下面的几个步骤:
- 输出提示内容,例如:
[epsda@ham-carrier ~]$,后面紧跟用户输入的指令 - 获取用户输入
- 将用户的输入拆分成单独的有效的字符串存入命令行参数表
- 创建子进程调用
exec家族函数调用用户输入的指令执行指定的程序
输出提示内容¶
根据系统shell的样式[epsda@ham-carrier ~]$,可以看出包括下面的内容:
- 用户名
@- 主机名
- 当前路径
- 用户提示符
$或者#
基本设计思路如下:
在系统环境变量中,存储着当前环境的用户名、主机名和当前路径,对于用户提示符,可以考虑判断是否是root用户,如果是则打印#,否则打印$
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
获取用户输入¶
获取用户输入可以有很多方法,但是如果直接使用scanf或者cin则无法一次性获取到用户输入的指令和选项,所以直接使用scanf和cin是不妥的,可以考虑使用使用fgets或者getline来代替
另外,因为不论是fgets还是getline,都默认以\n作为结束标志,但是需要注意,fgets尽管以\n结束,但是依旧会被读取到目标字符串中,但是getline不会,所以使用fgets一定要清除\n
需要注意的是,为了保证其他函数可以获取到输入的内容,可以定义一个数组存储输入的内容,但是这个数组不可以是一个局部变量,除非作为参数传递而不作为返回值,防止出现野指针问题
下面给出两种版本:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
拆分用户输入¶
所谓拆分用户输入,就是为了将用户输入的指令转换成单个字符串,因为指令和选项都是以空格分隔,所以可以考虑将空格作为分隔符,此处因为前面是使用字符数组作为存储字符串的载体,所以考虑使用C语言的strtok函数拆分
拆分出来的内容即为命令行参数,所以还需要一张命令行参数表,该表需要被子进程拿到,所以需要定义为全局变量
最后,因为是持续等待用户输入,所以下一次用户输入新的指令,需要覆盖前面的指令,所以需要对命令行参数个数和命令行参数列表全部重置
示例代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
执行对应程序¶
对于外部命令,需要创建一个子进程来执行,所以基本流程就是创建子进程,让子进程调用exec家族函数执行对应程序,这里推荐选用execvp函数,而对于父进程来说,只需要等待子进程执行结束回收子进程即可
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
内建命令处理¶
前面四个步骤已经完成了一个基本的shell,在Linux中,绝大部分的命令都是外部命令,但是前面提到除了外部命令还有内建命令,例如cd、echo、export等,而内建命令是不可以交给子进程处理的,因为子进程处理只是改变子进程的状态,不会影响父进程,而cd、echo、export这些命令本质修改的就是当前父进程的属性,所以为了保证这些内建命令生效,需要单独对这些命令进行处理
最简单的处理方式就是在子进程执行前进行判断,如果是内建命令就直接由当前进程执行,而不交给子进程,本次分别处理下面的内建命令:
cd命令export命令env命令
cd命令处理¶
cd命令的主要作用是更改当前的工作路径,所以当用户执行cd命令时,程序内部需要执行chdir函数来更改当前的工作路径cwd,示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
处理完cd命令可以发现尽管更改了工作路径,但是终端提示内容没有改变,原因是当前终端提示内容是程序加载时从父进程(系统shell)继承的环境变量,此时不论多少次获取,都只会读取到程序启动时的继承环境变量,所以pwd的值自始至终都是最开始启动的值,为了解决这个问题,可以将getenv函数换成getcwd函数
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
单独处理回到家目录的情况:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
export命令处理¶
export命令是将指定的环境变量导入到当前进程对应的环境变量表,所以也不可以交给子进程处理,当前模拟的shell所有的环境变量均是与系统shell共享的,因为并没有修改,一旦修改,就会发生写时拷贝,为了让模拟的shell拥有自己的环境变量,可以在程序启动时,加载父进程的环境变量到当前的模拟shell程序中,再处理export命令
模拟的shell复制系统shell的环境变量示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
处理export命令如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
env命令处理¶
env本质就是遍历当前进程的环境变量,因为当前模拟的shell进程的环境变量表已经拷贝完成,所以只需要遍历拷贝后的环境变量表
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
echo命令处理¶
本次修改的echo主要考虑两种情况:
echo $?:打印上一次进程的退出信息码echo 字符串:打印指定字符串
对于第一种,考虑创建一个全局变量接收每一个指令执行后的退出码,对于内建命令使用自定义退出码,对于外部命令通过status变量和相关的宏操作获取
对于第二种,考虑直接打印字符串即可
示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | |
优化¶
修改了父进程的环境变量后,子进程应该拿到的是当前父进程的环境变量,所以将开始的execvp函数改为execvpe函数:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
观察终端提示符可以发现,模拟的shell程序会显示从根路径一直到当前路径,为了尽可能还原,可以考虑将获取到的字符串按照/进行截取,一共分为两种情况:
- 在根目录:路径只有一个
/ - 不在根目录:最后一个目录是所需
所以可以考虑将最后一个/作为标志,反向取出字符,直到遇到最后一个/,单独处理根目录的情况即可,示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
手撕一个简单的shell(版本2)在Linux中输入和输出基本过程中,版本2主要添加了重定向功能