Linux进程间通信¶
约 8015 个字 888 行代码 11 张图片 预计阅读时间 38 分钟
进程间通信介绍¶
进程间通信,就是让进程之间可以访问同一个资源,但是进程本身是具有独立性的,所以直接让两个进程访问同一个资源是做不到的
Note
需要注意,尽管父子进程可以访问到全局变量,但是这个变量如果子进程要修改就会发生写时拷贝,最后导致两个进程看到的实际上并不是同一个全局变量
既然从进程角度出发无法直接做到,就需要考虑通过「第三方」进行,此处的「第三方」就是操作系统。从某一个角度来看,操作系统是所有进程所共享的资源
进程间通信在Linux中有下面的作用:
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
进程间通信本质上属于本地通信,即在同一台主机、同一个操作系统下进行的通信,对应着就有三种标准,根据进程间通信的发展,最先出现的就是管道方式通信,其次就是System V进程间通信一直到现在的POSIX进程间通信
其中,管道方式通信有下面两种:
- 匿名管道
- 命名管道
System V进程间通信有下面三种:
- System V消息队列
- System V共享内存
- System V信号量
POSIX进程间通信有下面6种:
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
管道介绍¶
在介绍匿名管道前,先了解何为管道:
管道是Unix/Linux中最古老的进程间通信的形式,把从一个进程连接到另一个进程的一个数据流称为一个「管道」。在前面Linux常用选项和指令已经介绍过管道的基础使用,此处进一步探讨管道到底是如何执行的
以下面的命令为例:
| Bash | |
|---|---|
1 | |
这个指令的作用是:统计当前使用Linux系统有多少个用户登录。其中,who显示当前登录的用户和其他信息,wc用于代表word count,可以用来统计给定文件中的字节数、字数、行数等,其中的-l表示只输出行数
上面的命令执行过程如下:

为了揭示管道左右两侧的命令的本质,可以执行下面的命令:
| Bash | |
|---|---|
1 | |
后台执行符号&
当在命令末尾加上&符号时,它会让该命令在后台运行,这样就可以立即得到命令行提示符,并可以继续输入其他命令而不必等待前面的命令完成。当一个进程在后台运行时,系统会提示后台运行的任务号和进程PID,如下图所示:
如果进程在后台运行,就不可以使用Ctrl+C终止,此时可以考虑使用kill指令终止,也可以通过fg -任务号将进程移动到前台再使用Ctrl+C终止
上面命令的作用是:同时启动睡眠计时器,并让二者在后台运行
执行上面的指令后使用下面的指令查看sleep进程:
| Bash | |
|---|---|
1 | |
可以看到下面的结果:

观察到二者的均为进程,并且二者的父进程相同,说明管道左侧和右侧的指令都变为了进程,并且具有兄弟关系。根据这个现象,可以得出管道实际上就是为两个进程提供通信的方式
匿名管道¶
匿名管道介绍¶
对管道有了了解后,接下来就可以了解何为匿名管道
在前面学习文件时,当文件需要被一个进程打开时,操作系统会根据进程的CWD找到文件所在目录,再根据文件名和inode编号映射找到对应的文件将其加载到内存,此时在文件视角会创建对应的struct file,在进程视角会存在进程PCB和files_struct,其中存在fd_array,并在fd_array的空位置存储文件指针,为了可以进行文件内容写入和读取,打开文件后也会创建对应的文件内核级缓冲区,如下图所示:
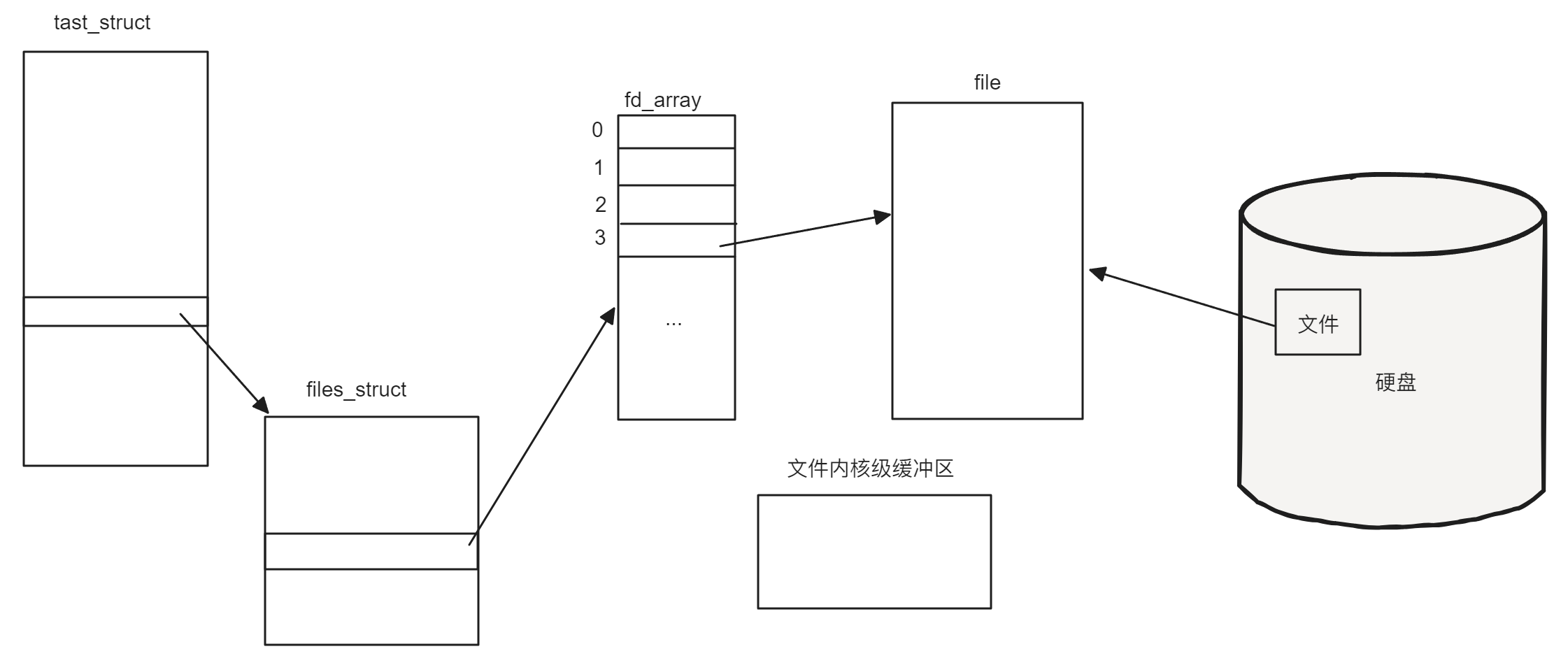
如果此时的进程创建了一个子进程,那么在子进程不修改数据的前提下,子进程会拷贝父进程的task_struct、files_struct(包括fd_array)以及struct file,但是子进程不会再次打开父进程已经打开的文件,也就是说,对于文件内核级缓冲区和已经从磁盘加载到内存的文件来说,子进程和父进程是共享的
Note
子进程之所以要拷贝struct file是为了保证子进程也可以向文件中写入数据,在struct file中存在文件偏移量,当子进程修改这个文件偏移量时只有在不与父进程共享的前提下才可以做到父进程和子进程在文件的不同位置写入数据
何时关闭文件
当一个进程打开了一个文件,那么正常情况下,在该进程结束后,这个文件会自动被操作系统释放,那么操作系统是如何知道这个文件已经没有进程在访问的,其实是通过struct file中的一个称为「引用计数」的属性,这个属性子进程并不会修改,只有这个引用计数为0时,操作系统才会自动释放文件。进程也可以调用关闭文件的接口关闭文件,例如close()
既然子进程和父进程共享一个文件内核级缓冲区,那么此时这个文件内核级缓冲区就是子进程和父进程两个进程所共享的资源,也就满足了进程间通信的前提条件:「进程间共享同一个资源」,并且这个资源并不是由子进程或者父进程提供,而是由操作系统提供的,所以也就不会因为进程独立性导致一个进程修改另外一个进程看不到的情况
但是现在的问题就是每一次父子进程需要通信就必须先打开一个磁盘中存在的文件,这个过程就会有点繁琐并且如果频繁做IO也会影响到系统整体的效率。为了解决这个问题就需要考虑一种存在于内存中的结构,这个结构不需要实际存在于硬盘中,也就想到了直接使用一个匿名的文件内核级缓冲区。这便是匿名管道「匿名」的由来
既然是文件内核级缓冲区,就说明可以直接调用文件相关的接口直接操作,但需要保证这个文件内核级缓冲区不自动刷新,否则可能读端还没读取到内容数据就已经丢失了。其中「直接调用文件相关的接口」也是最开始想到使用文件内核级缓冲区作为通信介质的原因
「管道」的由来
之所以叫这个作为进程通信介质的文件内核级缓冲区为「管道」是因为最开始只想到一端向另一端发送数据,也就是一方写入一方读取,即所谓的单向通信,在现实生活中,管道大部分便是一端进一端出,所以将其命名为「管道」
创建匿名管道¶
在Linux中创建匿名管道按照下面的步骤:
- 父进程调用系统调用接口
pipe()打开匿名的文件内核级缓冲区,其中pipe()接口中传递一个两个元素的数组,数组的第一个元素表示读端,第二个元素表示写端,返回值为一个整数,返回0表示打开成功,-1表示打开失败 - 父进程创建子进程
- 因为管道只能单向通信,所以只能读写或者写读,如果是读写,那么父进程就需要关闭写,子进程就需要关闭读,这一步并不是必须的,但是如果不关闭可能会出现误操作导致数据错误
Note
注意,不可以颠倒步骤1和步骤2,因为只有父进程创建了文件内核级缓冲区,子进程才能拷贝其文件描述符表和文件结构
根据上面的步骤可以写出下面的代码(以父进程读,子进程写为例):
-
父进程调用
pipe()接口C++ 1 2 3 4
int fd_pipe[2] = {0}; // 1. 父进程调用pipe int ret = pipe(fd_pipe); -
父进程创建子进程
C++ 1 2
// 2. 父进程创建子进程 int pid = fork(); -
父进程关闭写端,子进程关闭读端
C++ 1 2 3 4 5 6 7 8 9 10 11 12 13
// 3. 父进程关闭写端,子进程关闭读端 if (pid == 0) { // 子进程 // 子进程关闭读端 close(fd_pipe[0]); } else { // 父进程 // 父进程关闭写端 close(fd_pipe[1]); }
现在,子进程向匿名管道中写入数据,为了保证父进程看到的数据是动态变化的,可以使用一个计数器count,子进程向父进程写入一串字符串,父进程读取该字符串,完整示例代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | |
部分输出结果如下:
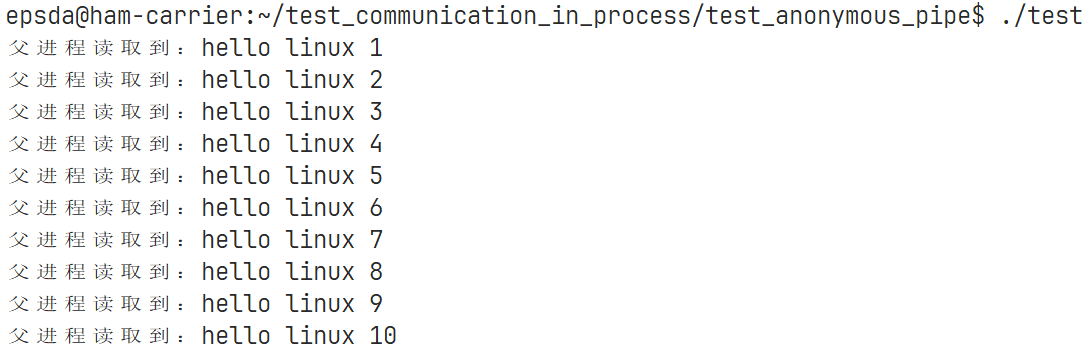
从上面的运行结果可以看到,尽管子进程在一直修改count变量,父进程依旧可以正常读取到修改后的count,现在基本上就实现了父子进程通信
匿名管道的特点¶
在Linux中,匿名管道有如下四个现象:
- 如果当前匿名管道为空且正常,那么此时读端就会等待,直到匿名管道中存在数据
- 如果当前匿名管道为满(在Ubuntu下是64KB)且正常,那么此时写端就会等待,直到匿名管道重新有空间
- 如果匿名管道的写端关闭,但是读端还在读取,那么此时读端相当于读取到文件结尾结束读取
- 如果匿名管道写端正常写入,但是读端关闭,那么操作系统会直接关闭写端进程,关闭的方式就是通过发送
SIGPIPE(编号为13)信号
匿名管道的特点:
- 面向字节流
- 用来进行父子等具有“血缘”关系的进程进行进程间通信
- 匿名管道的生命周期同文件的生命周期
- 单向数据通信
- 管道带有同步互斥等保护机制(从上面的现象1和2可以看出)。因为匿名管道属于共享资源,只要是共享资源就会有「数据不一致」问题,此时就必须要有对应的策略对这个资源进行保护,通常这个被保护的资源也被称为临界资源(即在一个时间段内只能有一个进程访问的资源),而访问临界资源的代码片段也被称为临界区
何为面向字节流
当提到匿名管道具有「面向字节流」的特点时,这意味着:
- 无消息边界:匿名管道处理的数据被视为连续的字节流,而不是离散的消息。发送方可以写入任意数量的字节到管道中,而接收方则从管道中读取这些字节。但是,读取操作并不保证会一次性读取所有写入的数据;每次读取可能返回任意数量的字节,直到所有数据都被读取完毕。因此,应用程序需要自行管理如何将字节流重新组合成有意义的消息
- 顺序性:字节流中的字节保持它们被写入时的顺序。也就是说,第一个写入管道的字节将是第一个被读出的字节(FIFO, First In First Out),这确保了数据传输的顺序不会被打乱
- 不可寻址性:由于是面向字节流的,所以不能像文件那样随机访问或定位到特定位置读写数据。你只能从当前的位置开始读或写,且一旦读取后,这些数据就被消费掉了,不能再次读取
- 半双工通信:传统上的匿名管道是单向的,即数据只能在一个方向上流动。如果需要双向通信,则必须创建两个管道,每个管道负责一个方向的数据传输。然而,某些现代操作系统提供了全双工的匿名管道
- 阻塞性质:当一个进程尝试从管道中读取数据但管道为空时,该读取操作会被阻塞,直到有数据可读为止。同样地,如果管道已满(尽管大多数现代系统对管道容量很大,几乎不会出现这种情况),写入操作也会被阻塞,直到有足够的空间来容纳新数据
- 有限缓冲区:虽然理论上可以认为管道能处理无限量的数据流,但实际上每个匿名管道都有一定的缓冲区大小。当缓冲区满时,写入操作会被阻塞直到有足够空间可用
Note
在Linux系统下,对于匿名管道来说存在一个PIPE_BUF宏,该宏指定了在匿名管道中,如果一次写入的数据小于PIPE_BUF的值,那么这个写入过程就是原子性的,即整个写入过程不会被其他进程向同一管道的写入操作所打断
匿名管道的应用(进程池)¶
有了匿名管道之后,就可以通过实际的案例来体会匿名管道在进程通信中的作用,本次以进程池的例子作为演示
在前面手撕shell中,每一次执行一个命令时,父进程会将该命令交给子进程进行处理,如果有多个命令就需要创建多个进程,例如执行who | wc -l命令。为了避免在每一次执行时都需要重新创建子进程,可以考虑提前创建好子进程,再由父进程将任务派发给指定的进程,此时的所有进程构成的就是一个进程池。当一个任务被提交到进程池中时,池中的空闲进程会取出任务并开始执行。一旦完成,该进程又回到池中等待下一个任务,示意图如下:
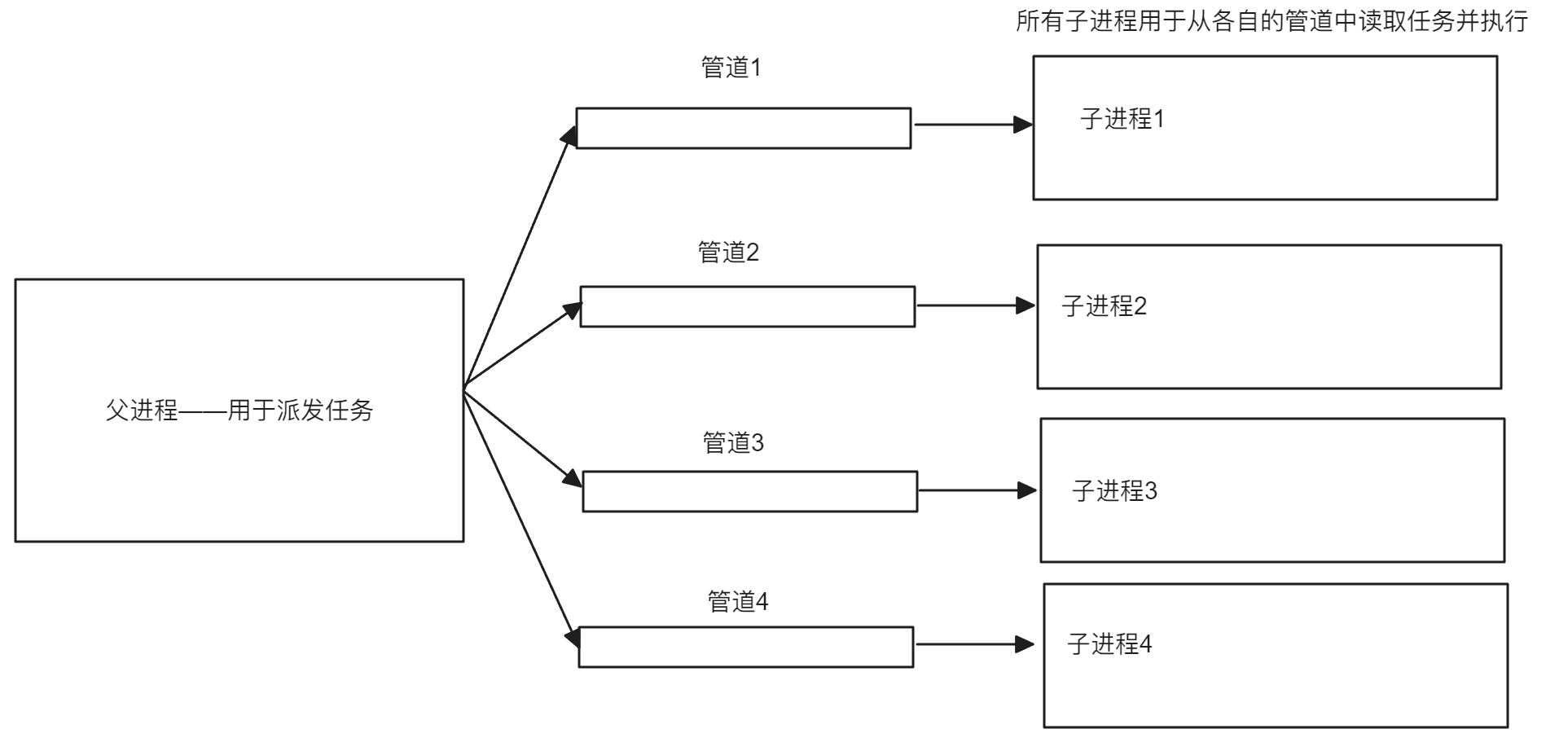
根据上面的描述,本次设计进程池分为下面的步骤:
- 创建进程池
- 父进程派发任务
- 销毁进程池
在本次实现进程池时,可能并不是使用.cpp或者.h的文件后缀,例如C++源文件使用.cc而不是.cpp,C++头文件使用.hpp而不是使用.h。下面是常见的C++源文件和头文件的后缀以及各自的区别:
-
源文件(Source Files):
.cpp:这是最常用的C++源代码文件扩展名。它包含了程序的主要实现部分,包括函数定义、类成员函数的实现等。编译器会直接编译这些文件来生成目标代码.cc或.cxx:这些也是用于表示C++源文件的扩展名,虽然不如.cpp常见,但在某些项目或组织中可能会用到。它们与.cpp文件的作用相同
-
头文件(Header Files):
.h:传统上,这是C语言头文件的扩展名,但它也被广泛应用于C++项目中。头文件主要用于声明,比如函数原型、宏定义、结构体定义等。它们通常不包含实现代码,而是提供给其他源文件包含(通过#include指令),以便共享声明信息。.hpp或.hxx:这些是专门为C++设计的头文件扩展名,用来区别于C语言的头文件。.hpp可能更常用一些。这类文件除了可以包含声明外,有时也会包含模板的定义或者其他仅在编译时需要的信息,因为模板的实现通常必须在编译时可见.hh:另一个较少见的C++头文件扩展名
为了当前项目可以更方便编译,下面是当前项目的通用Makefile:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
在上面的Makefile中,-Wall表示展示所有warning信息
Abstract
本项目先用面向过程的思想进行编写,再将面向过程的代码转换为面向对象的代码
创建进程池¶
通过用户输入获取进程池中进程的个数
为了可以自定义进程池中进程的个数,可以考虑通过从命令行中获取子进程个数,假设进程池项目可执行文件名为process_pool,那么正确的使用方法如下:
| Bash | |
|---|---|
1 | |
为了达到上面的效果,可以写出下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
如果上面的if语句未进入,说明使用方式正确,执行后面的代码
创建指定个数个子进程
创建子进程使用fork()接口,创建子进程对应的管道使用pipe()接口,具体使用方式在前面已经提及,下面主要讨论如何管理管道和对应的子进程
因为需要根据指定个数创建子进程,所以少不了要使用循环控制,考虑在循环中创建管道数组可以保证每一次的数组都存储不同的值,但是弊端就是除了每一次循环结束管道数组就会销毁,所以父进程就需要对管道数组进行统一管理,因为父进程是向子进程派发任务,所以父进程可以考虑只管理写端接口,此处可以考虑直接使用一个vector存储每一个管道写端的文件描述符,但是为了更好的进行管理以及添加属性和功能,可以为管道创建一个类,下面是管道的示例类:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
创建进程池的步骤由父进程来完成,所以在父进程中执行循环,循环体内父进程先创建管道并创建子进程,子进程关闭写端,父进程关闭读端,为了保证子进程执行完任务后退出,可以使用exit()接口。最后,前面将管道定义为了一个类,这个过程只是做到了「先描述」,接下来就是根据子进程pid和对应的写端创建管道对象并插入到vector中完成「后组织」,整个过程的代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
上面的代码中,关于错误处理的返回值,可以考虑使用C语言的枚举定义对应的错误码:
| C | |
|---|---|
1 2 3 4 5 6 7 | |
所以,上面的代码也可以修改为:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
另外,在C++ 11中,提供了emplace_back接口,可以直接在插入的过程中自动构建指定类的对象,所以可以使用emplace_back简化构造Channel对象并push_back到vector的过程,即:
| C++ | |
|---|---|
1 2 3 4 5 6 7 | |
上面的代码仅仅是完成了一部分,因为子进程只是创建了但还没有真正执行任务,并且因为使用了exit()接口结束了进程且父进程没有回收,此时就会出现所有子进程僵尸状态,因此,可以考虑创建一个主任务,该主任务的特点是所有子进程都必须执行的任务,既然是所有子进程都要执行的任务,那么根据前面的设定:子进程需要从管道中读取数据,所以所有子进程都要执行的任务就是读取,为了保证一直在读,考虑使用死循环,所以子进程的主任务代码框架如下:
| C++ | |
|---|---|
1 2 3 4 | |
具体子进程读到什么,读多少内容在接下来设计派发任务时再具体叙述。当子进程进入read()函数时,只要管道中没有数据,那么根据管道的特点,此时读端就会阻塞直到管道有数据为止
考虑接下来的问题:如果这个主任务并不是直接写在子进程的if语句中,而是单独作为一个函数,那么此时就必须知道当前子进程对应的管道的文件描述符,也就是说如果主任务抽象为一个函数,那么函数的参数就必须传递一个整数,所以为了简化这个步骤,可以在子进程读取任务之前,先将子进程的读取过程进行重定向,本次考虑重定向到标准输入,此时函数参数就可以不需要表示管道文件描述符的整数了,基本框架如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
至此,创建进程池的基本框架已经形成,为了代码具有复用性,不应将创建进程池的代码直接放在main函数中,所以可以将其抽离到单独的函数中:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
最后,上面的代码还可以进行功能性的优化,如果未来不想让子进程只能执行work(),可以考虑使用函数指针(在C++中就是包装器)构成回调函数,因为上面的代码是基于C++的,所以接下来就直接使用包装器而不是函数指针,所以上面的整体代码可以修改为:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | |
Note
为了确保上面的代码没有问题,可以考虑使用下面的代码进行测试:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
注意上面的代码需要在Channel类中实现getName()函数:
| C++ | |
|---|---|
1 2 3 4 | |
为了保证子进程不会变为孤儿进程,需要确保主进程不会提前结束,可以考虑使用sleep()
父进程派发任务¶
创建任务
前面提到,在创建进程池时,子进程都需要执行一个主任务,但是子进程需要执行的子任务并没有确定,而是需要等待父进程进行分派,本次为了演示方便一共准备三个任务,并且三个任务只是简单的输出,不会涉及到具体的逻辑实现:
| C++ | |
|---|---|
1 2 3 4 5 | |
| C++ | |
|---|---|
1 2 3 4 5 | |
| C++ | |
|---|---|
1 2 3 4 5 | |
有了子任务,父进程就需要考虑如何管理任务,同样可以创建一个TaskManager的类,这个类负责向子进程分派任务。本次实现中为了让子进程更好得从管道中获取到指定的任务,考虑使用任务编号(本次设置为整型)表示每一个任务,即:0表示下载任务,1表示上传任务,2表示修改任务。为了实现这种映射关系,可以使用unordered_map或者map,因为主要是查询任务,所以使用unordered_map效率更高。
接着需要考虑到一个问题,前面已经使用了main_task表示返回值为void、不接受参数的主任务函数,所以不可以再使用using对同类型的包装器进行声明。为了解决这种冲突,本次考虑创建一个新的文件,后缀为.hpp
例如下面的代码:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | |
在上面的代码中,使用宏定义确保头文件不会被重复包含:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
在TaskManager类中,通过成员方法insertTask在构造函数执行时将全局域中的三个子任务插入到哈希表并建立任务和编号映射,这里需要注意,此处的包装器包装了返回值为void、没有参数的函数,如果三个子任务为TaskManager类的成员函数,那么尽管显式情况下的函数返回值为void、没有参数,也无法插入到task_count中,因为成员函数含有隐藏的参数this,所以本次为了方便,将子任务放在全局作用域
分派任务
上面的步骤只是完成了任务的创建,接着就需要考虑父进程如何派发这三个任务,分派任务给子进程的方式有很多种,本次主要考虑轮询分派给每一个子进程,所谓轮询分派,就是一个接着一个、循环分派
为了实现分派,父进程首先必须要从TaskManager中获取到任务编号并写进管道,否则子进程无法拿到任务,所以需要在TaskManager中添加获取编号的方法。这里获取任务编号的方式有很多种,也可以考虑使用轮询的方式获取编号,本次考虑使用随机数,为了简便,考虑使用C语言中的随机数获取方式:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
接着就是在TaskManager添加根据指定任务编号执行任务的函数:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
有了获取任务编号和根据任务编号执行的函数后,就需要父进程将获取到的任务编号写入管道,再由子进程从管道(已重定向为标准输入)中读取任务,所以需要在Channel类中添加相关的函数,同时为了便于在其他位置调用TaskManager类中的方法,在Task.hpp中创建一个TaskManager类对象:
| C++ | |
|---|---|
1 2 3 | |
| C++ | |
|---|---|
1 2 3 4 5 6 | |
上面的步骤只是编写了父进程发送任务的接口,并没有真正发送任务,所以接下来就是发送任务的逻辑,同样,为了保证复用性,直接将逻辑抽离放在单独的函数中:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
父进程发送任务后,子进程的主任务就可以开始进行读取,所以主任务修改为:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
销毁进程池¶
在前面提到,如果管道关闭,那么读端就会读取到文件结尾,即读取到的数据长度为0,所以可以利用这个特点结束子进程的任务,将进程池中所有的管道关闭再回收子进程就可以完成进程池的销毁,具体步骤如下:
- 父进程关闭管道
- 父进程回收子进程
父进程关闭管道
父进程想要关闭管道就需要关闭对应的写端,在Channel类中存在_wfd属性,利用该属性即可关闭对应管道的写端,即:
| C++ | |
|---|---|
1 2 3 4 5 | |
接着父进程通过管道对象数组结构依次关闭管道,即:
| C++ | |
|---|---|
1 2 3 4 5 6 | |
父进程回收子进程
在关闭所有管道后,即可关闭所有依次回收所有子进程,在Channel类中存储了进程的pid,所以可以通过在Channel类中实现获取pid的接口:
| C++ | |
|---|---|
1 2 3 4 | |
在销毁进程池的函数中插入回收子进程的逻辑:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
最后,当父进程关闭写端后,子进程从管道中读取到的内容长度为0,所以可以通过判断read()接口返回值是否为0判断是否退出主任务:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
细节优化¶
上面的代码中存在一个比较深层的bug,如果按照上面的销毁进程池代码写法不会暴露出问题,但是如果将该代码修改为如下代码就会出现无法回收到子进程导致父进程一直等待:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
版本2的代码和版本1的代码的区别就在于版本2只使用了一个for循环同时完成关闭管道和回收子进程,版本1使用了两个for循环分别进行关闭管道和回收子进程
使用版本2的代码后为了可以看到运行效果,考虑父进程派发10次任务后不再派发任务,结果如下:

之所以会出现这个问题,本质就是因为在创建进程池时,如果只有一个父进程和一个子进程那么子进程拷贝父进程的文件描述符表时只会有两个值,一个表示写,一个表示读,父进程关闭读端,子进程关闭写端,如下图所示:
Note
注意,下面所有图中文件描述符表的数字都是下标,对应的真正下标为蓝色文字,为了更容易理解,将下标直接作为填充值,所以下标顺序错乱
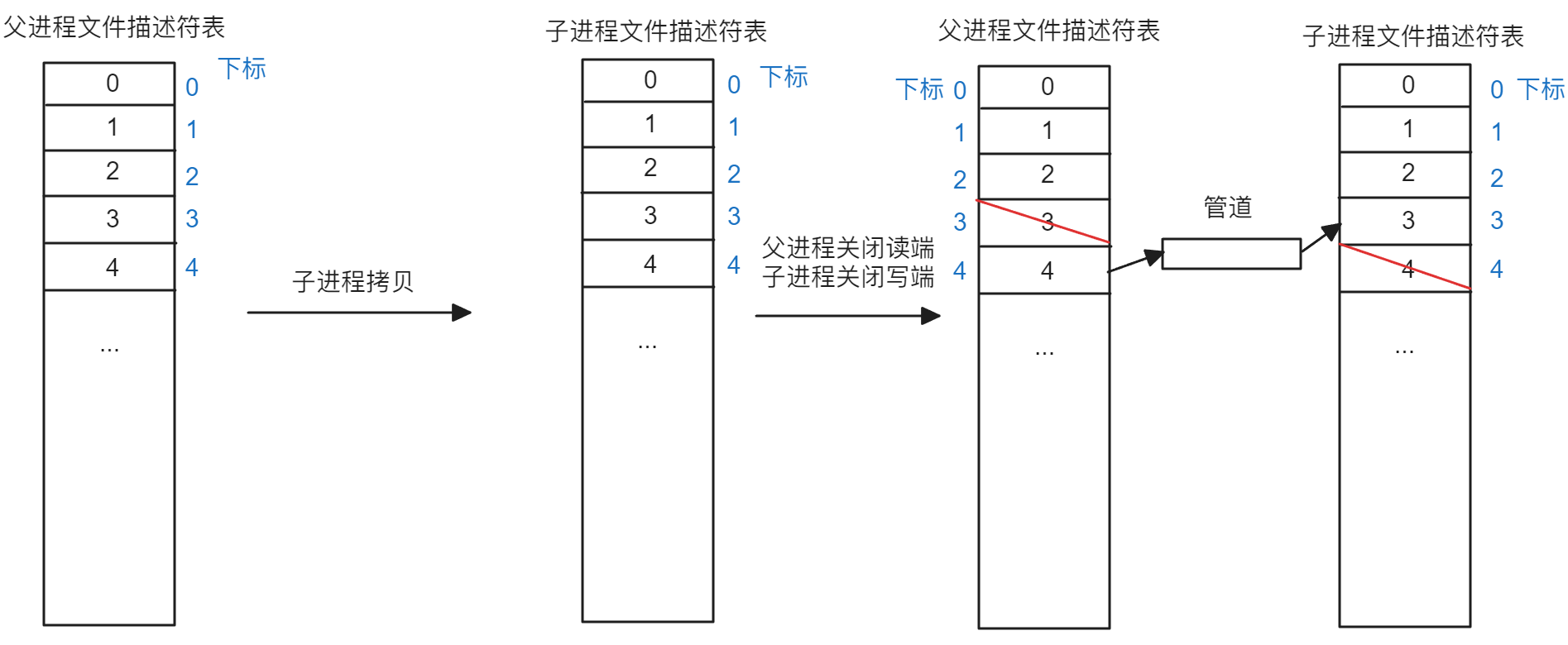
但是如果增加到两个子进程,那么此时父进程又会开辟一个新的管道数组存储管道读端和写端,子进程也会拷贝对应的值,如下图所示:
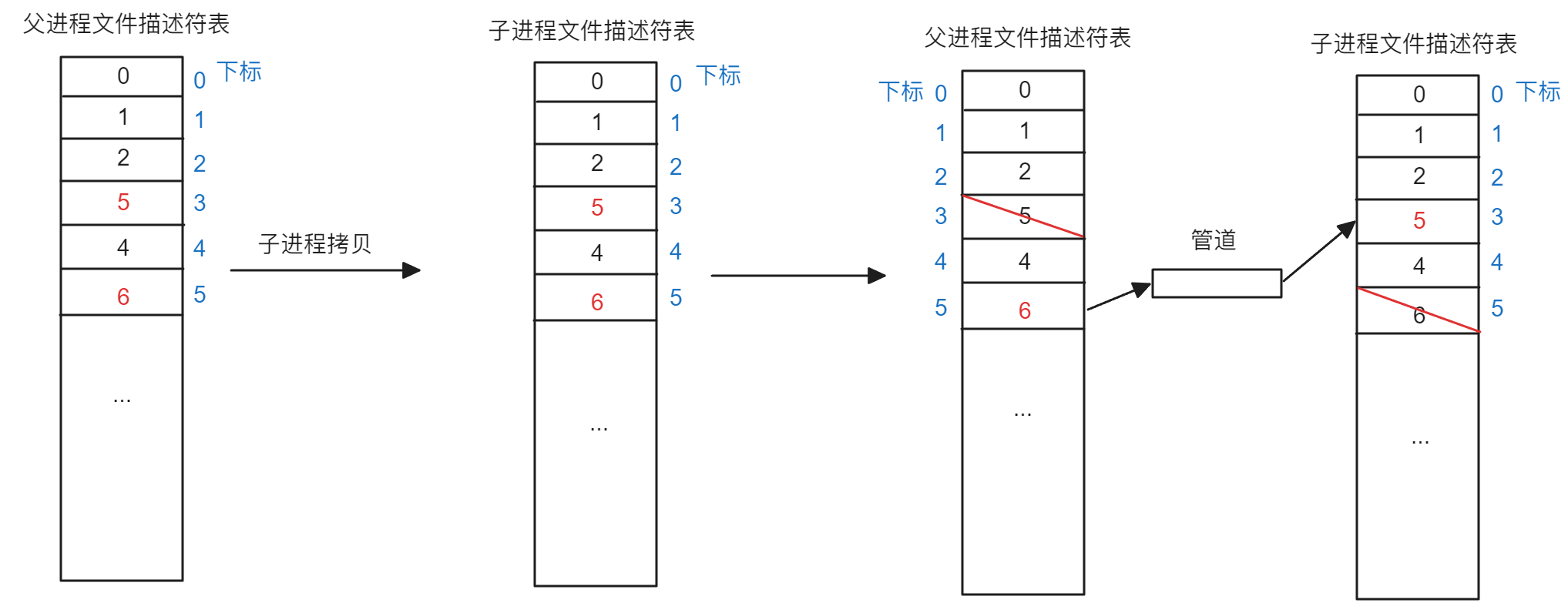
从上图可以看出,当同一个父进程创建第二个子进程后,第二个子进程也会保留一开始的4号端口
为了便于观察,将两幅图合并为一副图:
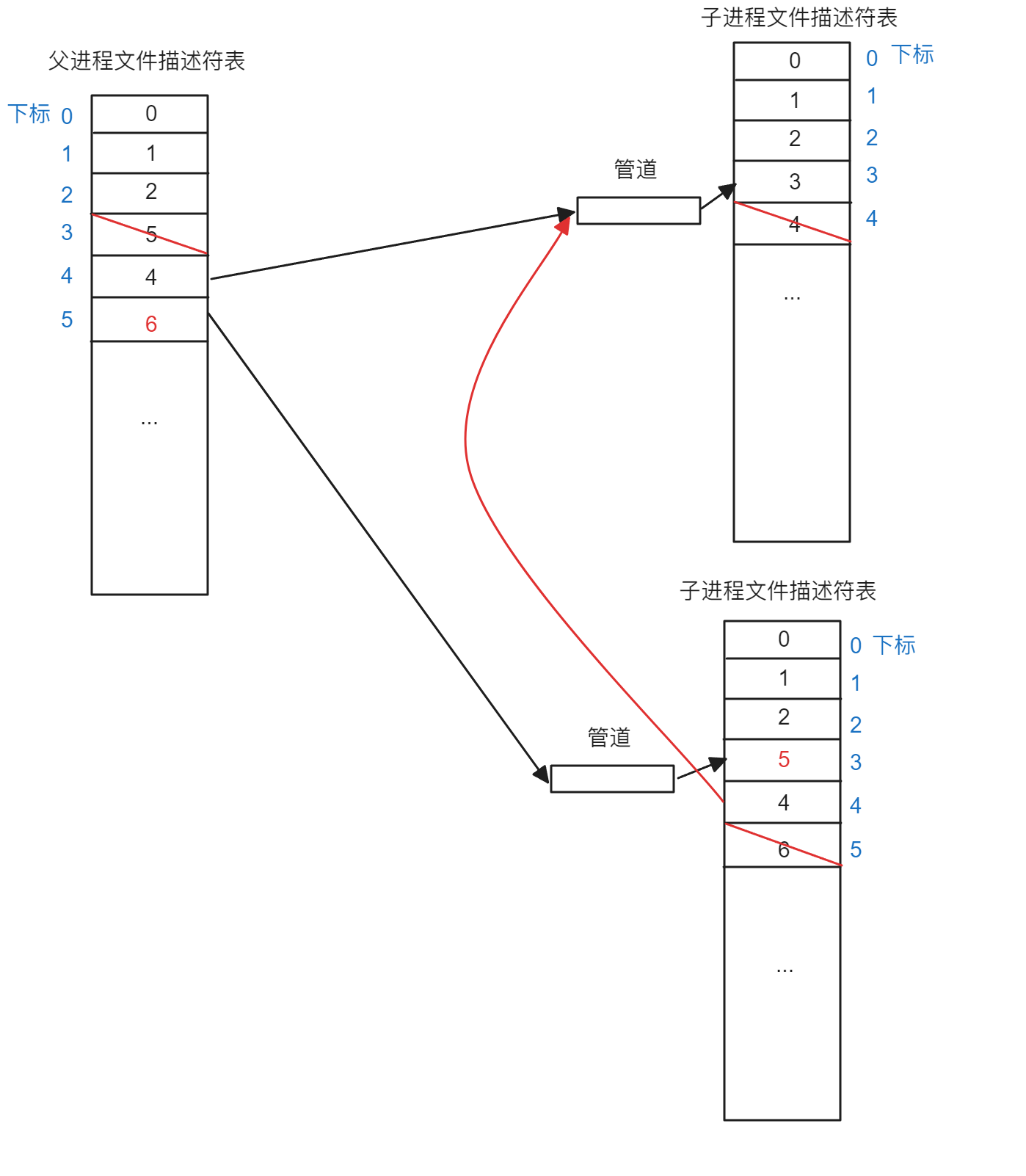
可以看到,不但有父进程的4号指向第一个进程的管道写端,第二次拷贝文件描述符表的子进程也有4号文件描述符指向第一个进程的管道写端,问题就在这里,按照上面代码销毁进程池的逻辑,先关闭管道,接着就回收子进程,但是根据上面的图可以看到,第一次关闭管道时父进程只会关闭自己的文件描述符表中的4号,但是因为第二个子进程的文件描述符表的4号还指向第一个进程的管道写端,所以导致第一个进程认为自己还应该有数据而不会退出主任务,从而导致waitpid()接口一直处于等待状态,最后展现的就是开始的结果图。根据上面的原理依次类推,如果再创建一个进程,那么第一个子进程的管道写端就会有一个父进程和两个子进程共同指向,第二个进程的管道写端就会有一个父进程和一个子进程共同指向,以此类推,如果有\(n\)个子进程,那么第一个子进程会有\(n\)个进程(包括父进程在内)指向其管道写端,第二个子进程就会有\(n-1\)个进程(包括父进程在内)执行其管道写端
解决这个问题的方法有两种:
- 从最后一个子进程(管理管道的数组结构的最后一个元素)开始关闭
- 在创建进程池时,子进程关闭所有拷贝的写端
下面采取第二个方法解决,既然是所有拷贝过来的写端,那么管道结构一定保存了对应的写端文件描述符,所以只需要将其依次关闭即可:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
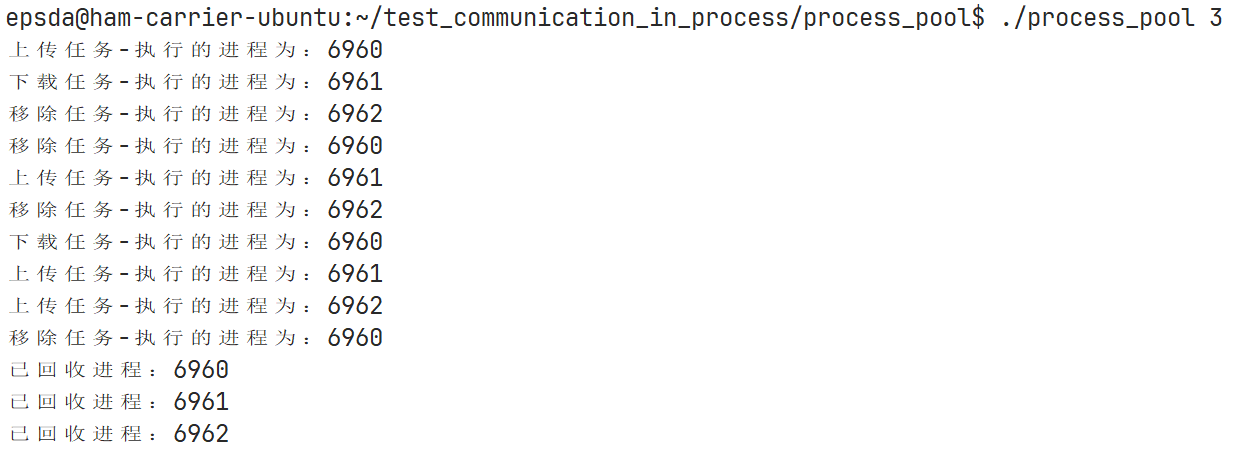
再次编译运行可以看到问题已经解决:
面向过程转面向对象¶
面向过程转面向对象本质就是将属于各类的方法和成员放到一个模版中,并使用对象去调用,下面根据上面的步骤,可以划分出下面的类:
- 进程池类
ProcessPool:包括进程池初始化、进程池销毁、主任务以及任务派发,放到ProcessPool.hpp文件下 - 任务类
TaskManager:已存在 - 管道类
Channel:已存在,但是放到Channel.hpp文件中
最后,单独创建Main.cc文件存放main函数,整体代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | |