序列化和反序列化与网络计算器¶
约 5334 个字 572 行代码 4 张图片 预计阅读时间 25 分钟
何为序列化和反序列化¶
在前面UDP编程和TCP编程中,客户端和服务端之间传递的信息都是字符串,那么是否可以传递一个结构化的数据,例如前面聊天室中,传递一个类似于下面结构化的数据:
| C++ | |
|---|---|
1 2 3 4 5 | |
实际上,如果是同一台计算机下,直接传递是完全可以的,因为同一台计算机对一个数据的封装和还原都是使用的同一个方式,但是在网络中,网络可能涉及到不同的操作系统,不同的计算机,其中就可能涉及到对结构化数据的设定,例如结构体的内存对齐问题,所以在网络中不建议之间传递结构化的数据,尽管在某些情况下可以
既然不能使用结构化数据,但是又可以使用字符串形式的数据,那么有没有一种方式可以将二者结合?这个方式就是序列化,所谓序列化就是将结构化的数据转换为一种约定格式的字符串。既然可以将结构化的数据进行序列化,那么当另一方拿到这个序列化后的数据又改如何处理呢?利用反序列化,反序列化就是序列化的反向操作,即将约定格式的字符串转换为结构化的数据
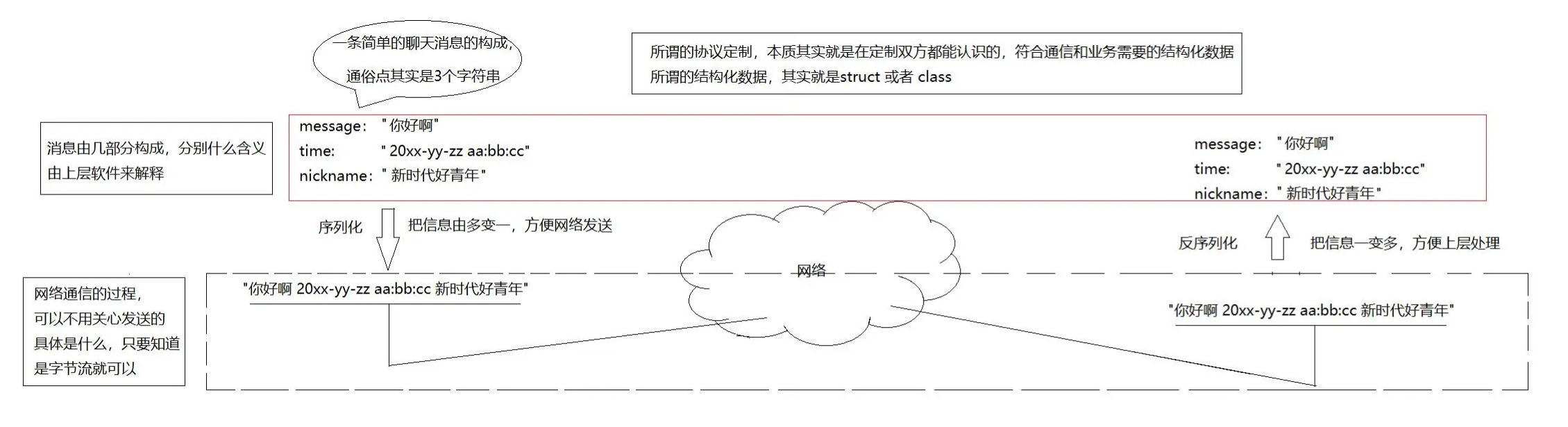
现在可以传递结构化的数据,那么为了保证客户端和服务端都能正确读取到具体的数据,就必须要保证客户端和服务端都使用同一个结构体,在这整个过程中,使用同一个结构就代表双方使用的是同一个协议。所以,所谓的协议就是结构化的数据。而因为这个结构都是定义在具体的应用中,所以这个协议属于应用层协议
上面的内容对应示意图如下:
如何理解socketfd全双工¶
在前面介绍UDP和TCP时都提到了socketfd是全双工的,但是为什么他们是全双工的?以TCP为例,TCP在底层维护了两个缓冲区,分别是发送缓冲区和接收缓冲区。当客户端向服务端发送数据时,客户端发送数据的接口会将数据拷贝到发送缓冲区,接着由操作系统决定如何以及何时发送客户端发送缓冲区的数据,一旦这个数据发送给服务器,服务器就会将接收到的数据拷贝到服务器的接收缓冲区,而服务器端的写接口一旦发现其接收缓冲区有数据就会将接收缓冲区的数据拷贝到上层;同样的,当服务器向客户端发送数据时,服务端的写接口就会将数据拷贝到发送缓冲区,接着由操作系统决定如何以及何时发送服务端发送缓冲区的数据,一旦这个数据发送给客户端,客户端就会将接收到的数据拷贝到客户端的接收缓冲区,而客户端的写接口一旦发现其接收缓冲区有数据就会将接收缓冲区的数据拷贝到上层
整个过程的示意图如下:
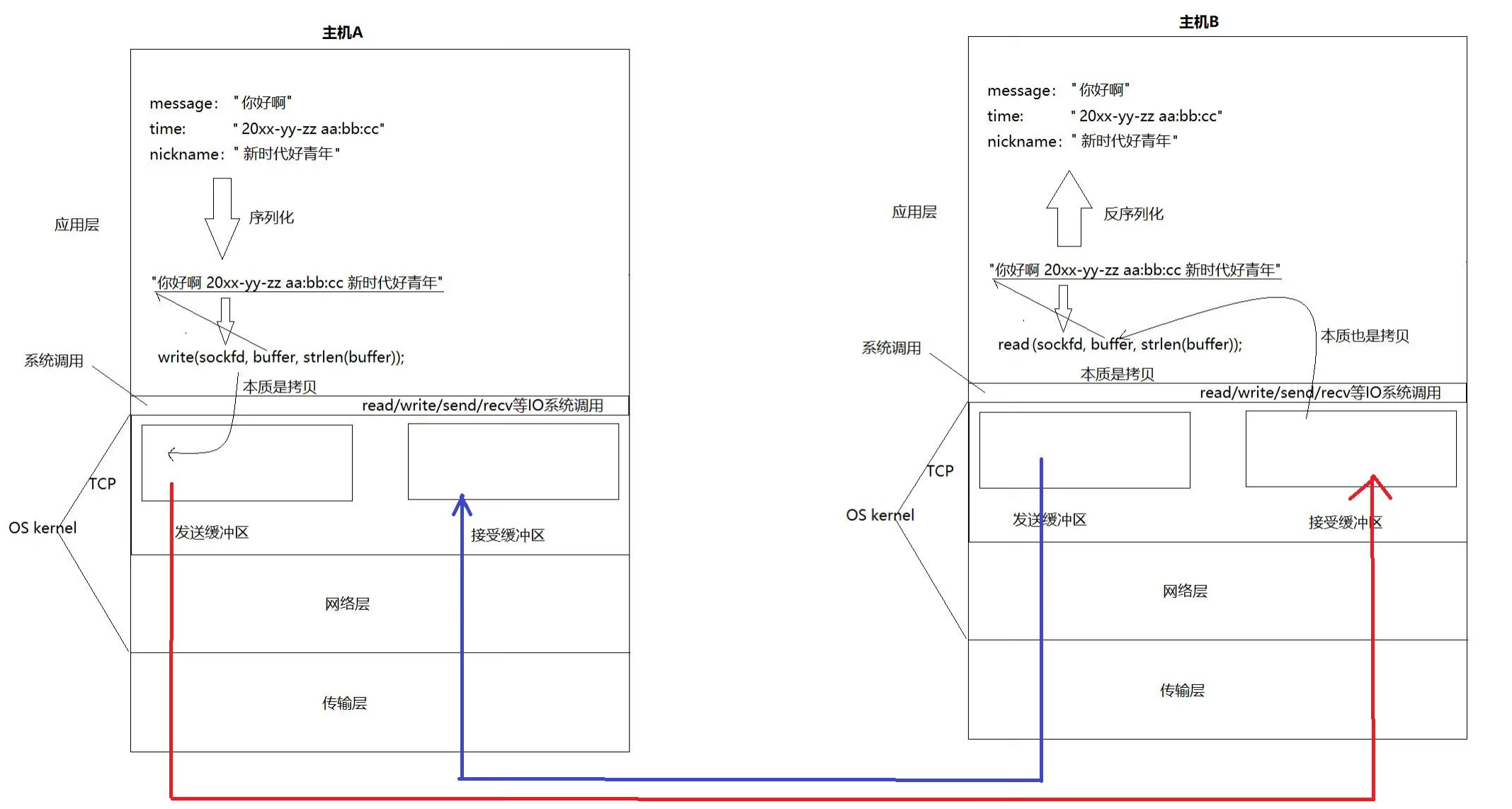
所以,所谓的全双工本质就是利用两个缓冲区,客户端的发送缓冲区对应服务端的接收缓冲区,服务端的发送缓冲区对应客户端的接收缓冲区
但是,如果有多个客户端同时给服务端发送数据,那么服务端又该如何处理这些数据呢?这里就需要对这些数据进行管理,在操作系统底层,先对这些数据进行描述,即构建一个消息结构,再将这些消息结构对象链接到一张链表中,这样操作系统对数据的管理就转换为了对链表的CURD,既然接收缓冲区需要有对应的链表,那么发送缓冲区也需要有对应的链表,这张链表就是对待发送的多条数据进行管理。对应的Linux源码如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
如何理解面向字节流和面向数据包¶
现在将视角集中到客户端向服务端发送的一条信息之上,因为TCP是面向字节流的,所以在客户端给服务端发送数据时可能存在发送的数据只有待发送数据的一半甚至更少,那这样服务端接收到数据就属于不完整的数据,在上面应用层转换时也就可能转换失败。基于这个原因,所以说TCP的读写,不论是使用文件流的read和write,还是网络中的recv和send都是不完善的,因为这些接口不会检测数据是否是上层需要的有效数据,而且这些接口也无法做到判断数据是否是上层需要的有效数据,所以这就需要应用层自己判断收到的数据是否是可以被正确转换的,如果不是就应该继续接收直到至少有一条有效数据
但是对于UDP来说就不存在上面TCP这个问题,因为UDP是面向数据包的,所谓数据包就是将数据整个打包,在发送时要么就发整个数据包,要么就一点也不发,这样不论是哪一个接口,拿到的都是完整的数据
网络计算器¶
上面已经基本介绍了一些概念,下面基于TCP实现一个网络计算器,通过这个计算器更深刻得去理解上面的概念
网络计算器的基本功能就是客户端发送计算表达式(本次只实现五种运算,分别是:+、-、*、/和%),服务端接收到计算表达式后通过相关接口对这个表达式进行处理并将结果返回给客户端
定义客户端和服务端协议¶
为了方便处理,本次考虑客户端和服务端都使用结构化的数据,既然是结构化的数据,那么就必须使用到序列化和反序列化。为了保证客户端和服务端看到同一个结构,就需要定义两个类,分别为请求类和响应类,其中请求类包含三个字段:第一个操作数、第二个操作数和操作符,响应类包含两个字段:计算结果和结果状态(正常计算或非正常计算的原因)
当客户端发送数据给服务端时需要进行序列化,此时服务端就会收到一个字符串,但是前面提到过,TCP是面向字节流的,所以可能存在服务端收到的字符串并不是完整的或者是存在至少一个完整表达式的,对于并不是完整表达式的字符串,服那么这个表达式就无法被正确计算出结果,而对于存在至少一个完整表达式的,就需要提取其中的完整表达式
现在就出现了另外一个问题,何为一个完整表达式?首先,例如3+、+2等肯定不是完整表达式,那3+22+2属于完整表达式吗?3+22+2到底是3+2和2+2还是3+22和+2,对于这种模棱两可的不论是按照哪一种方式进行处理都属于处理不当,所以在本次实现中,除了需要对结构化的数据进行序列化和反序列化外,还需要对序列化后的数据进行编码和对反序列化前的数据进行解码,此处考虑一种比较简单的编码方式,即在序列化的字符串前后添加\n,即\n3+2\n,除了这样,再考虑在第一个\n前添加一个数字,这个数字代表的就是序列化后的字符串的长度,例如3\n3+2\n。这样做就可以保证第一个\n前面的数字一定是用于表示序列化后的字符串的长度,而最后一个\n就是这个表达式的结尾。在解码过程中先找到一个\n,这个\n前的就是之后的序列化字符串的长度,只要没读取到等于这个长度的字符串就属于没有读取到完整的表达式,当读取到序列化字符串的长度加最后一个\n的长度就属于读取到一条有效的可以进行解码的字符串
完成上面的步骤之后就完成了客户端和服务端之间定义协议
实现客户端和服务端协议¶
基本结构¶
根据上面的思路,可以实现Request和Response类基本结构:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
设计请求类¶
对于请求类来说,主要需要实现的就是序列化和反序列化。在C++中,实现序列化和反序列化的方式有很多种,本次以JSON字符串为例,后面的其他项目会考虑使用别的序列化工具例如protobuf
本次使用的JSON转换方案为jsoncpp库,基本使用和介绍见关于JSONCPP库
对于序列化函数,参数为一个输出型参数,将当前类中的字段组合为一个完整的JSON字符串,再将该字符串赋值给输出型参数即可,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
对于反序列化函数,参数是一个输入型参数,对应的是一个序列化字符串,将序列化字符串中的相关字段转换为原始数据赋值给对应成员即可,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
设计响应类¶
与请求类一致,主要设计序列化和反序列化方法
对于序列化函数来说,基本思路与请求类中的序列化函数一样,但是需要注意的是,因为计算状态类并不属于内置类型,所以考虑提供一个get和一个set方法分别提供计算状态类转换为int的逻辑和int转换为计算状态类的逻辑:
| C++ | |
|---|---|
1 2 3 4 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
其中,对于get方法可以考虑在计算状态类中提供int()重载函数代替,对于set函数可以将判断逻辑简化为之间判断num是否小于0或者大于3,一旦满足二者任意一个就说明是错误计算状态类型
有了上面的两个函数后,就可以分别设计序列化函数和反序列化函数:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
实现编码和解码方法¶
在上面的两个类中,只提供了序列化和反序列化的方法,并没有提供解码和编码的方法,主要原因是解码和编码逻辑对于两个类来说都是一致的,都是对一个序列化字符串进行编码和未被反序列化字符串进行解码,所以没必要在两个类都写解码和编码
考虑编码函数,根据上面定义的客户端和服务端协议,编码后的字符串格式应该为JSON字符串长度\n{json}\n,所以编码只需要将对应内容拼接到对应的位置即可:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
考虑解码函数,根据编码字符串格式JSON字符串长度\n{json}\n,解码函数需要处理的逻辑就是将其中的json字符串提取出来,但是直接提取是不对的。因为前面提到TCP是面向字节流的,所以实际上传递给解码函数的字符串可能是不完整的,也有可能是至少有一个可以提取的字符串,对于不完整的字符串来说,解码函数就不能继续向后执行解码逻辑,但是对于至少有一个可以提取的字符串来说,只需要将其中完整的部分提取出来解码,剩下的再次判断是否完整再决定是否可以继续解码
首先,找到传入字符串的第一个\n出现的位置,其前面的值就是json字符串的长度,如果没找到这个位置或者获取到的值为0,那么就没有必要再继续进行解码,返回false;接着,计算出json字符串的长度+两个\n的总长度,如果这个总长度小于前面获取的到值,说明也无法进行解码,返回false
有了这两步就可以排除字符串不完整的情况,此时就只剩两种情况:刚刚好是需要的完整字符串或者至少存在一个可以提取的字符串,对于这两种基本的处理方式都是一样的,只需要在其中提取到有效的json字符串即可,以至少存在一个可以提取的字符串为例,因为已经获取了JSON字符串的长度,所以只需要从第一个\n的下一个位置开始截取,一直到JSON字符串长度值为止即可。但是因为至少存在一个可以提取的字符串,所以可能剩余部分还有可以提取的字符串,为了避免重复提取,需要将当前已经提取的未解码的字符串从传入的字符串中移除
Note
需要注意,建议传入的字符串设置为引用类型,这样可以确保自始至终都在修改一个字符串
根据上面的思路,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
修改服务端¶
在上一节中,服务端主要由线程池执行对应的任务,而对于线程池执行的任务来说固定为读取消息的read_write_msg函数,在本次实现的网络计算器中,为了保证每一个模块之间的耦合度降低,考虑将序列化反序列化任务和编码解码任务交给上层而不是服务器本身需要做的事情,服务器本身只需要做好IO即可
根据这个思路,首先服务器的启动逻辑不需要改变,依旧是使用线程池执行对应的任务:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
但是在读写函数中,因为本次服务端只是负责接收客户端发送的信息,虽然接收到的是一个已经编码的字符串,但是并不对这个字符串进行直接处理,而是交给上层处理,处理完成后将结果返回给客户端。但是需要注意,如果读取到的字符串是空串就需要服务端继续读取,所以基本代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
设计计算器类¶
计算器类非常简单,只需要将收到的内容进行计算,再将结果返回即可。但是,收到的内容并不直接是操作数和操作符,返回值也并不直接是一个计算结果,而应该分别是请求类对象和响应类对象,之所以这样设计,是因为计算器类本质已经算是最上层了,既然服务端和客户端传输的是结构化的数据,那么在计算的时候也使用结构化的数据保证整体统一。所以,计算器类基本结构如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 | |
既然计算器类已经是最上层,那么解码和编码操作以及序列化和反序列化操作不需要计算器类来做,所以在calculate方法中只需要根据具体的操作符计算出结果即可。为了保证可读性,可以将计算状态根据状态码转换为对应地字符串,这个函数可以考虑在响应类中定义:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
另外,为了方便获取到操作数和操作符以及获取和设置计算结果,需要提供对应的get和set:
| C++ | |
|---|---|
1 2 3 4 | |
| C++ | |
|---|---|
1 2 3 4 | |
| C++ | |
|---|---|
1 2 3 4 | |
| C++ | |
|---|---|
1 2 3 4 | |
| C++ | |
|---|---|
1 2 3 4 | |
对应地calculate函数实现如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
修改服务端主函数逻辑¶
修改服务端上层的逻辑需要考虑到三点:
- 根据客户端传递的字符串进行解码和反序列化
- 计算有效表达式结果
- 将有效结果表达式返回给客户端
这里可以设计一个类ServerEntry,代表服务器需要执行的入口函数,在这个类中,存在一个函数,这个函数主要是为了将字符串反序列化和解码、获取结算结果和字符串序列化和编码。其中,计算有效表达式结果交给计算器类完成,这样可以确保复用性和可维护性,也可以保证低耦合度,所以考虑也使用回调函数的方式将计算方式交给上层
不考虑计算逻辑后,下面只需要考虑对字符串进行处理的逻辑,首先是解码获取到其中的JSON字符串,但是需要注意,解码是否成功是个循环逻辑,因为可能存在收到的字符串是残缺的、完整的或者至少存在一个可以提取到有效JSON字符串的字符串。在循环内部就是对已经解码的字符串做相关处理,其中可以对获取到的JSON字符串进行判断是否为空决定是否继续向后进行,因为已经解码,所以下一步就是反序列化,如果反序列化失败就不再继续,否则就调用上层接口执行计算逻辑,再对收到的内容进行序列化和编码
所以代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
最后,在服务端的主函数内部,只需要定义三层对象,分别是计算类对象用于执行计算任务、入口类对象用于执行解析字符串任务和服务端对象用于进行IO操作,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
修改客户端¶
客户端的逻辑和服务端类似,同样考虑将如何处理结果交给上层,代码如下:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | |
修改客户端主函数逻辑¶
与服务端主函数逻辑一样,需要一个入口类,但是这个入口类中的入口函数比较简单,只需要将服务端发送的序列化和编码的字符串解码和反序列化返回即可:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
接着同样的方式修改客户端主函数:
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
测试¶
根据上面的代码,编译生产可执行程序,运行服务端和客户端,可以得到类似下面的结果:

图表梳理¶
类间关系¶
classDiagram
%% 协议相关类
class Request {
-int _first
-int _second
-char _op
+Request()
+Request(int f, int s, char op)
+serialize(string& out) bool
+deserialize(string& in) bool
+getFirst() int
+getSecond() int
+getOp() char
}
class Response {
-int _result
-CalculatStatus _c_stat
+Response()
+Response(int ret, CalculatStatus c)
+getCalStatusNum(CalculatStatus& c) int
+setCalStatusNum(int num)
+getResult() int
+setResult(int ret)
+getCalStatusStr() string
+serialize(string& out) bool
+deserialize(string& in) bool
}
class Calculator {
+calculate(const Request& req) Response
}
%% 网络相关类
class TcpServer {
-int _listen_socketfd
-uint16_t _port
-bool _isRunning
-shared_ptr~ThreadPool~task_t~~ _tp
-cal_t _cal
+TcpServer(cal_t cal, uint16_t port)
+start()
+stop()
+read_write_msg(sockaddr_in peer, int ac_socketfd)
+~TcpServer()
}
class TcpClient {
-int _socketfd
-string _ip
-uint16_t _port
-bool _isRunning
-handler_t _handler
+TcpClient(handler_t handler, string ip, uint16_t port)
+start()
+stop()
+~TcpClient()
}
%% 入口类
class ServerEntry {
-calculate_t _calculate
+ServerEntry(calculate_t cal)
+entry(string& encodedStr) string
}
class ClientEntry {
+ClientEntry()
+entry(string& encodedStr) string
}
%% 线程池类
class ThreadPool~T~ {
-vector~Thread~ _threads
-size_t _num
-queue~T~ _tasks
-bool _isRunning
-Mutex _lock
-Condition _cond
-int _wait_num
-static shared_ptr~ThreadPool~T~~ _tp_ptr
-ThreadPool(int num)
-bool isEmpty()
-get_executeTasks()
+static getInstance(int num) shared_ptr~ThreadPool~T~~
+startThreads()
+waitThreads()
+pushTasks(T task)
+stopThreads()
}
%% 枚举类
class CalculatStatus {
<<enumeration>>
Initial
Normal
DividedByZero
ModByZero
WrongExpression
}
%% 工具函数
class ProtocolFunctions {
<<function>>
+encode(string& message) bool
+decode(string& encodedstr, string& jsonstr) bool
}
class SetDaemon {
<<function>>
+daemon(bool ischdir, bool isclose)
}
%% 关系连接
Response --> CalculatStatus : 使用
Calculator --> Request : 使用
Calculator --> Response : 返回
ServerEntry --> Request : 处理
ServerEntry --> Response : 返回
ServerEntry --> ProtocolFunctions : 调用
ClientEntry --> Response : 处理
ClientEntry --> ProtocolFunctions : 调用
TcpServer *-- ThreadPool : 包含
TcpServer --> ServerEntry : 调用
TcpClient --> Request : 创建
TcpClient --> ClientEntry : 调用
TcpClient --> ProtocolFunctions : 调用执行逻辑¶
服务器端¶
sequenceDiagram
participant Client as 客户端
participant Server as TcpServer
participant ThreadPool as ThreadPool
participant ServerEntry as ServerEntry
participant Calculator as Calculator
Client->>+Server: 发送计算请求
Server->>+ThreadPool: pushTasks(read_write_msg)
ThreadPool-->>-Server: 任务入队
ThreadPool->>+Server: read_write_msg(peer, ac_socketfd)
Server->>Server: recv()接收请求数据
Server->>+ServerEntry: entry(encodedStr)
ServerEntry->>ServerEntry: decode(encodedStr, jsonstr)
ServerEntry->>ServerEntry: req.deserialize(jsonstr)
ServerEntry->>+Calculator: calculate(req)
Calculator->>Calculator: 执行计算
note over Calculator: 根据操作符执行不同计算
note over Calculator: 处理除零等特殊情况
Calculator-->>-ServerEntry: 返回Response
ServerEntry->>ServerEntry: resp.serialize(out)
ServerEntry->>ServerEntry: encode(out)
ServerEntry-->>-Server: 返回编码后的响应
Server->>Server: send()发送响应
Server-->>-ThreadPool: 处理完成
Server-->>Client: 发送计算结果客户端¶
sequenceDiagram
participant User as 用户
participant Client as TcpClient
participant Entry as ClientEntry
participant Server as 服务器
User->>+Client: 输入计算表达式(first op second)
Client->>Client: 创建Request(first, second, op)
Client->>Client: req.serialize(message)
Client->>Client: encode(message)
Client->>+Server: send(message)
Server->>Server: 处理请求
Server-->>-Client: 返回计算结果
Client->>+Entry: entry(encodedStr)
Entry->>Entry: decode(encodedStr, jsonstr)
Entry->>Entry: resp.deserialize(jsonstr)
Entry->>Entry: 构造结果字符串
Entry-->>-Client: 返回可读结果
Client->>User: 显示计算结果
Client->>Client: 继续等待用户输入理解为什么OSI七层模型优秀¶
首先,对比TCP/IP五层模型和OSI七层模型:
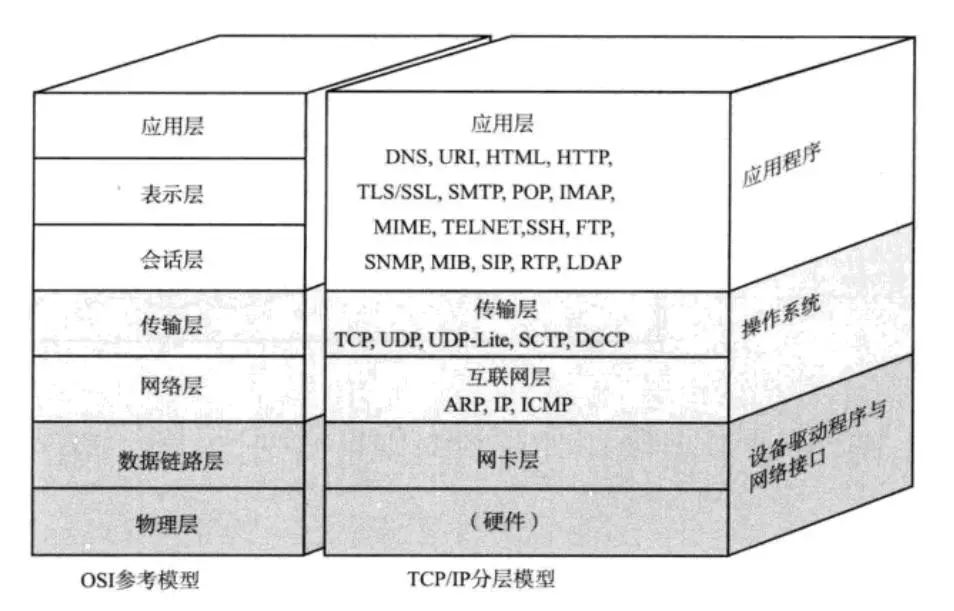
可以看到两者下4层是一样的,本质是因为这4层是由操作系统可以实现的,为了进行网络通信,下4层必须要一样
但是对于OSI七层模型的上三层来说:
首先是会话层,这一层实际上就是进行通信管理,这就是客户端和服务端如何进行通信进行定义,而这一部分需要利用到操作系统底层的接口,这也就对应着会话层管理下4层,这里就对应着网络计算器中客户端和服务端的设计
一旦客户端和服务端可以正常通信,接下来就是具体通信什么内容,这就需要表现层设定好传输内容的格式,确保客户端和服务端都可以认识彼此的数据并做出正确的解析,这里就对应着网络计算器中实现的序列化和反序列化以及编码和解码
最后就是设置传输的内容,也就是定义结构化数据,这里就对应着网络计算器中的请求类和响应类的字段
这三层,每一层都相互联系,但凡少一层都无法正确进行通信,而之所以TCP/IP协议将这三层压缩为一层,就是因为这三层是无法被操作系统具体实现的,属于操作系统之上的应用部分
所以,尽管大部分教科书提到OSI七层模型麻烦,但是其依旧出现在各大教科书中