深入HTTP序列化和反序列化
约 6267 个字 949 行代码 9 张图片 预计阅读时间 33 分钟
本篇介绍
在上一节已经完成了客户端和服务端基本的HTTP通信,但是前面的传递并没有完全体现出HTTP的序列化和反序列化,为了更好得理解其工作流程,在本节会以更加具体的方式分析到HTTP序列化和反序列化
基本实现思路
本次实现的HttpServer类主要完成接收客户端发送的HTTP请求,也就是说,服务器需要根据客户端的HTTP请求回复一个HTTP响应,所以必须要有的方法就是处理请求方法,但是前面已经提到过,HTTP的请求属于结构化的数据,并且这个数据在传递给服务器时就已经做了序列化,服务器需要处理的就是将结构化的数据进行反序列化;同样,服务器处理完毕后还需要发给客户端,所以此处就需要服务器对处理的结果填充到HTTP响应结构对象中再返回给客户端,此处就需要进行序列化
基于上面的原因,与前面序列化和反序列化与网络计算器一样,需要实现一个协议,包含HttpRequest和HttpResponse类,用于处理序列化和反序列化
HTTP不是自己做序列化和反序列化吗,为什么上面还需要手动进行序列化和反序列化
需要注意的是,HTTP自己做序列化前提是基于一个已经存在的HTTP服务器,首先对于客户端,如果是浏览器,浏览器会自动将传送给服务器的数据进行序列化,此时服务器必须要进行反序列化提取其中的有效内容,同样,因为实现的是HTTP服务器,所以现在的服务器本身不具备任何自动序列化的行为,需要手动去实现,因此实现的HttpServer必须将响应给客户端的数据进行序列化再发送给客户端,这样客户端才可以正常获取到HTTP响应中的数据
本次为了更好得理解序列化和反序列化,以HTTP请求为例,首先以请求行、请求报头和请求体三个整体做序列化和反序列化,接着再深入请求行、请求报头和请求体中的字段
根据这个两个阶段,需要实现的目标如下:
- 第一阶段:打印出反序列化和序列化的结果
- 第二阶段:向客户端返回具体的静态HTML文件
第一阶段
创建HttpRequest类
根据前面的基本思路,实现HttpRequest类就需要实现对应的反序列化。因为HTTP请求中带有三种数据:
- 请求行
- 请求报头
- 请求体
所以需要定义三个成员分别存放从请求获取到的内容,所以基本结构如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | class HttpRequest
{
public:
HttpRequest()
{
}
// 反序列化
bool deserialize(std::string& in_str)
{
}
~HttpRequest()
{
}
private:
std::string _req_line; // 请求行
std::vector<std::string> _req_head; // 请求报头
std::string _req_body; // 请求体
};
|
实现HttpRequest反序列化接口
在HTTP中的反序列化本质就是根据基本的格式去除掉多余的部分,从而提取出有效的数据放在相应的字段中,所以根据这个思路依次进行提取
Note
注意,前面提到过,HTTP是基于TCP的,而TCP是面向字节流的,这就导致可能服务器接收到的HTTP请求不完整,对此还需要对接收到的HTTP请求进行完整性判断,但是本次不考虑这一步
截取请求行
首先提取请求行中的数据,根据前面对HTTP请求结构的描述可以知道HTTP请求的请求行以\r\n结尾,所以只需要找到第一个\r\n,就说明找到了请求行,这里定义一个成员函数用来处理这个逻辑:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | // 获取请求行
bool parseReqLineFromTotal(std::string& in_str)
{
auto pos = in_str.find(default_sep);
if(pos == std::string::npos)
{
LOG(LogLevel::WARNING) << "未找到请求行";
return false;
}
// 获取到请求行
_req_line = in_str.substr(0, pos);
// 从原始字符串中移除请求头和第一个分隔符
in_str.erase(0, pos + default_sep.size());
LOG(LogLevel::DEBUG) << "请求行处理后:" << in_str;
return true;
}
|
这里考虑到后面的请求体也是以\r\n结尾,所以考虑将该函数更改为更通用的版本:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 截取以\r\n结尾的数据
bool parseOneLineFromTotal(std::string& in_str, std::string& out_str)
{
auto pos = in_str.find(default_sep);
if(pos == std::string::npos)
return false;
// 获取到截取数据
out_str = in_str.substr(0, pos);
// 从原始字符串中移除截取的字符串和对应的分隔符
in_str.erase(0, pos + default_sep.size());
return true;
}
|
接着完善反序列化接口:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13 | // 反序列化
bool deserialize(std::string& in_str)
{
bool getReqLineFlag = parseOneLineFromTotal(in_str, _req_line);
if(!getReqLineFlag)
{
LOG(LogLevel::WARNING) << "反序列化获取请求行失败";
return false;
}
LOG(LogLevel::INFO) << "截取的请求行为:" << _req_line;
// 未完...
}
|
截取请求报头
截取请求报头的方式与请求行非常类似,无非就是需要多次截取,但是需要考虑截取何时结束。根据HTTP请求体的特点,最后一行就是一个空行,即\r\n,所以可以考虑利用这个空行进行处理,具体思路如下:
因为每一次截取都会截取到分隔符之前的内容,所以可以考虑定义一个变量用于接收请求报头的结果,那么根据截取一行的函数的逻辑,只有成功找到了\r\n时才会进行截取,而截取的结果不会包含\r\n,那么一旦截取的结果是空且找到了\r\n,就说明找到了最后一行
根据这个思路,将获取请求报头数据的逻辑放在一个单独的函数中,如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 | // 获取请求报头
bool getReqHeadFromTotal(std::string &in_str)
{
// 保存以\r\n结尾的一行数据
std::string oneLine;
while (true)
{
bool getOneLineFlag = parseOneLineFromTotal(in_str, oneLine);
// 如果getOneLineFlag为true并且oneLine不为空,说明当前行有效,否则代表已经找到了结尾
if(getOneLineFlag && !oneLine.empty())
{
_req_head.push_back(oneLine);
}
else if(getOneLineFlag && oneLine.empty())
{
break;
}
else
{
return false;
}
}
return true;
}
|
继续完善反序列化接口:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | // 反序列化
bool deserialize(std::string &in_str)
{
// ...
bool getReqHeadLine = getReqHeadFromTotal(in_str);
if (!getReqHeadLine)
{
LOG(LogLevel::WARNING) << "反序列化获取请求报头失败";
return false;
}
LOG(LogLevel::INFO) << "获取到的请求行为:";
std::for_each(_req_head.begin(), _req_head.end(), [&](std::string data){
std::cout << data << std::endl;
});
// 未完...
}
|
截取请求体
因为在前面截取请求行和截取请求报头时已经修改了HTTP请求字符串,所以剩下的就是请求体,直接赋值即可:
| C++ |
|---|
| // 反序列化
bool deserialize(std::string &in_str)
{
// ...
// 获取请求体
_req_body = in_str;
return true;
}
|
创建HttpResponse类
服务器需要给客户端返回内容,所以在这之前必须对整个HttpResponse结构进行序列化。同样,HTTP响应也有对应的三种数据:
- 请求行
- 请求报头
- 请求体
所以需要定义三个成员分别存放从请求获取到的内容,所以基本结构如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | // HTTP响应
class HttpResponse
{
public:
HttpResponse(std::string &rl, std::vector<std::string> &rq, std::string &rb)
: _resp_line(rl), _resp_head(rq), _resp_body(rb)
{
}
HttpResponse(std::string &rl, std::string &rb)
: _resp_line(rl), _resp_body(rb)
{
}
// 序列化
bool serialize(std::string &out_str)
{
}
~HttpResponse()
{
}
private:
std::string _resp_line; // 响应头
std::vector<std::string> _resp_head; // 响应报头
std::string _resp_body; // 响应体
};
|
实现HttpResponse序列化接口
实现serialize就会比实现deserialize接口简单,只需要根据对应的字段加上\r\n即可,所以基本代码如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | // 序列化
bool serialize(std::string &out_str)
{
// 给响应行添加\r\n
_resp_line += default_sep;
out_str += _resp_line;
// 给响应报头的每一个字段加上\r\n
std::for_each(_resp_head.begin(), _resp_head.end(), [&](std::string &str)
{
str += default_sep;
out_str += str; });
// 添加空行
out_str += default_sep;
out_str += _resp_body;
return true;
}
|
修改HttpServer类
只需要改变HttpServer类中的请求处理函数,但是如果要打印反序列的结果就必须提供对应的接口或者在HttpRequest类内提供打印函数,本次考虑后者:
| C++ |
|---|
| void print()
{
// 请求行
LOG(LogLevel::INFO) << "请求行:" << _req_line;
// 请求报头
std::for_each(_req_head.begin(), _req_head.end(), [&](std::string& str)
{ LOG(LogLevel::INFO) << "请求报头:" << str; });
// 请求体
LOG(LogLevel::INFO) << "请求体:" << _req_body;
}
|
接着修改HttpServer的handleHttpRequest函数:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | void handleHttpRequest(SockAddrIn sock_addr_in, int ac_socketfd)
{
LOG(LogLevel::INFO) << "收到来自:" << sock_addr_in.getIp() << ":" << sock_addr_in.getPort() << "的连接";
// 获取客户端传来的HTTP请求
base_socket_ptr bs = _tp->getSocketPtr();
std::string in_str;
bs->recvData(in_str, ac_socketfd);
// 反序列化
HttpRequest req;
req.deserialize(in_str);
// 打印反序列结果
req.print();
// 构建HttpResponse返回
std::string line = "HTTP 1.1 200 OK";
std::string body = "<h1>Build HttpResponse success</h1>";
HttpResponse resp(line, body);
std::string out_str;
// 序列化
resp.serialize(out_str);
LOG(LogLevel::INFO) << out_str;
bs->sendData(out_str, ac_socketfd);
}
|
测试
主函数与上一节一样,测试结果如下:
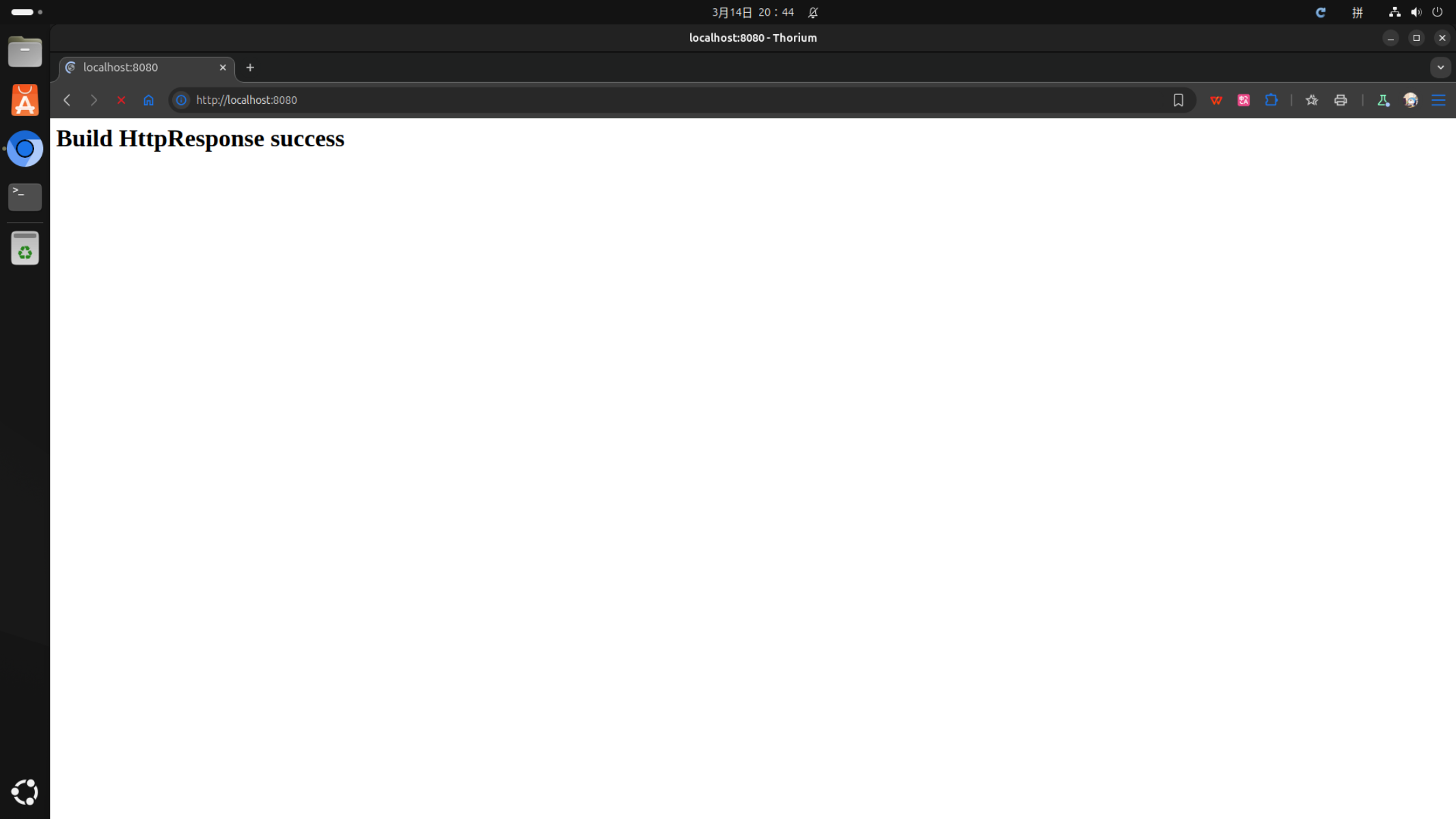
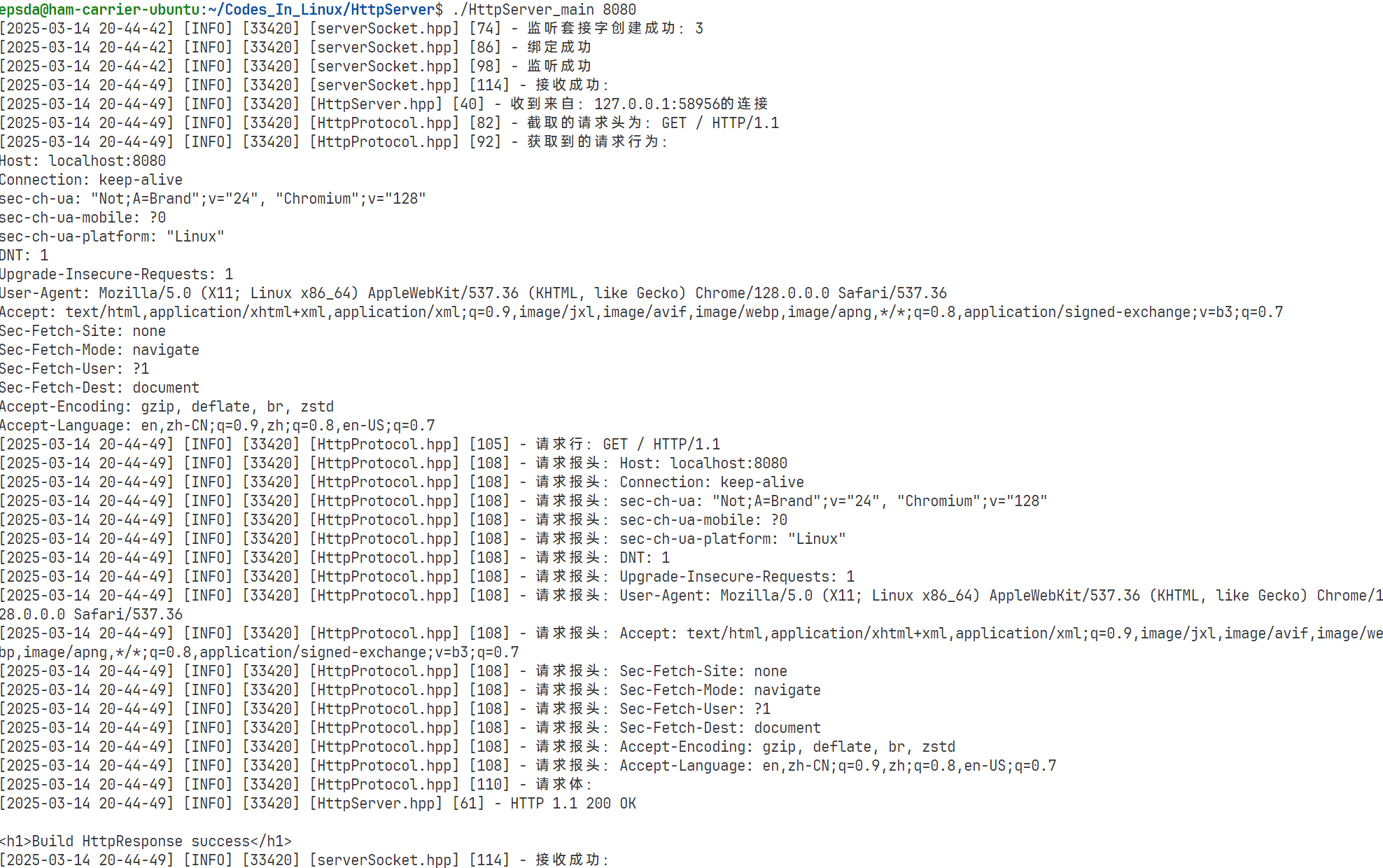
从上图可以看到可以成功获取到HTTP请求结果并且正常回复HTTP响应,第一阶段目标完成
第二阶段
在第一阶段的基础之上,现在需要对HTTP请求和HTTP响应的每一个字段进行细化,本次不考虑某个字段或者属性是什么含义,只需要将其进行提取即可
修改HttpRequest类
提取HTTP请求行中的字段
因为HTTP请求行中的每个字段是根据空格进行分隔的,回忆C/C++的输入和输出,默认也是以空白字符进行分隔,所以就可以利用这一点,可以使用C语言的sscanf()进行读取,也可以考虑使用C++的stringstream进行
因为需要读取到每个字段,所以需要对应的成员进行接收,这里就使用三个成员_req_method、_req_uri和_req_ver作为补充成员:
| C++ |
|---|
| class HttpRequest
{
public:
// ...
private:
std::string _req_method; // 请求方法
std::string _req_uri; // 请求资源路径
std::string _req_ver; // HTTP请求版本
// ...
};
|
接着就是实现一个函数用于从req_line中提取对应的字段填充_req_method、_req_uri和_req_ver三个成员:
接下来修改deserialize的逻辑:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | bool deserialize(std::string &in_str)
{
// 截取请求行
bool getReqLineFlag = parseOneLineFromTotal(in_str, _req_line);
if (!getReqLineFlag)
{
LOG(LogLevel::WARNING) << "反序列化获取请求行失败";
return false;
}
LOG(LogLevel::INFO) << "截取的请求头为:" << _req_line;
// 填充请求行的字段
getContentFromReqLine();
// ...
return true;
}
|
提取HTTP请求报头中的字段
前面完成了获取到HTTP请求报头中的每一条数据,但是请求报头实际上是key-value结构的数据,服务器需要拿到其中的key以及value进行后续的处理,所以这里就需要分别取出key和对应的value
为了存储对应的key和value,可以考虑使用一个哈希表。这里,因为处理每一个每一条报头数据不需要经过_req_head过渡,所以可以考虑直接将分割出的字符串传递给处理分隔的函数,在该函数中直接将对应的键值对添加到哈希表即可
Note
每一个键值对字符串以:<space>分隔,而不是:
首先完成分割逻辑:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | bool getPairFromReqHead(std::string& oneLine)
{
// 找到分隔符
auto pos = oneLine.find(default_head_sep);
// 左侧即为key
std::string key = oneLine.substr(0, pos);
// 右侧即为value
std::string value = oneLine.substr(pos + default_head_sep.size());
// 插入到哈希表中
_kv.insert({key, value});
return true;
}
|
接下来修改deserialize和getReqHeadFromTotal的逻辑:
提取HTTP请求体中的字段
保持和第一阶段的处理方式一样
修改HttpResponse类
第一阶段的HttpResponse类只是使用一个固定的字符串进行序列化再发送给客户端,这个做法明显是不妥的。实际上,对于HTTP响应来说,应该处理下面几点:
- 允许根据请求内容是否合法自动构建响应状态码,并且根据状态码自动生成状态码描述
- 允许外部添加响应报头中的属性
- 根据客户端请求的内容读取服务端存在的对应文件并返回给客户端,没有时返回404页面
HTTP状态码
根据上面的思路,首先需要处理的就是状态码,在介绍HTTP协议基本结构与基本实现HTTPServer一节提到,HTTP协议规定任何客户端的请求都必须得到响应,而区分响应情况就是通过状态码
在HTTP中,状态码有以下几种:
| 类别 | 原因短语 |
| 1XX | Informational(信息性状态码)接收的请求正在处理 |
| 2XX | Success(成功状态码)请求正常处理完毕 |
| 3XX | Redirection(重定向状态码)需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码)服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码)服务器处理请求出错 |
但是,仅有开头还不足以说明具体的问题,所以每一种类别下还有具体的状态码和对应描述,因为状态码太多,所以下面仅仅展示常见的状态码:
| 状态码 | 类别 | 描述 | 示例场景 |
| 100 | 信息响应 | 请求已接收,客户端应继续发送请求 | 客户端询问服务器是否支持某些功能 |
| 101 | 信息响应 | 切换协议 | 客户端请求切换到WebSocket协议 |
| 200 | 成功响应 | 请求成功 | 页面加载成功 |
| 201 | 成功响应 | 资源创建成功 | 创建新用户或上传文件 |
| 204 | 成功响应 | 请求成功但无内容返回 | 删除操作后不返回任何内容 |
| 301 | 重定向 | 永久重定向 | 网站迁移至新域名 |
| 302 | 重定向 | 临时重定向 | 用户登录后跳转到主页 |
| 304 | 重定向 | 资源未修改,使用缓存 | 浏览器缓存的资源未过期 |
| 400 | 客户端错误 | 请求无效或无法被服务器理解 | 请求参数缺失或格式错误 |
| 401 | 客户端错误 | 未授权访问 | 用户未提供身份验证 |
| 403 | 客户端错误 | 禁止访问 | 用户权限不足 |
| 404 | 客户端错误 | 资源未找到 | 请求的页面或API不存在 |
| 405 | 客户端错误 | 方法不允许 | 使用了不支持的HTTP方法(如POST代替GET) |
| 429 | 客户端错误 | 请求过多 | 超过API速率限制 |
| 500 | 服务器错误 | 内部服务器错误 | 服务器代码逻辑出错 |
| 502 | 服务器错误 | 错误网关 | 服务器作为网关时收到无效响应 |
| 503 | 服务器错误 | 服务不可用 | 服务器过载或维护中 |
| 504 | 服务器错误 | 网关超时 | 服务器作为网关时未能及时从上游获取响应 |
更多状态码和对应描述表
| 状态码 | 状态码英文描述 | 中文含义 |
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
其中,更为常见的就是200(OK)、404(Not Found)、403(Forbidden)、302(Redirect)和504(Bad Gateway)
本次优先考虑200(OK)和404(Not Found),对于重定向将在后面的章节介绍,此处不具体描述
处理响应行
首先是HTTP响应版本,这个字段可以设置为一个固定值,因为一般情况下只会在升级的时候更改,所以可以考虑使用一个字符串指定
接着是HTTP响应状态码和状态码描述,因为本次只考虑200和404,所以只有两种情况:
- 用户请求的资源存在
- 用户请求的资源不存在
根据这两种情况,需要考虑的问题就是如何判断用户请求的资源是否存在。前面提到,URI就是资源路径,也就是说,用户想要拿到的资源就在URI中。根据这一点得出「判断用户请求的资源是否存在」只需要「在当前服务器的资源目录中找到对应的文件是否存在」即可。现在的问题就转变为「如何判断一个文件是否存在」,这里可以使用文件流读取对应的文件,如果文件不存在就给用户返回一个空字符串,否则就将读取到的文件添加到结果字符串即可
根据上面的思路,首先就是要获取到URI,这一点其实在HttpRequest中已经做到了,所以在HttpResponse中需要获取一下即可,这里可以考虑让读取内容的函数接收一个URI字符串,所以获取文件内容函数的基本逻辑如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | // 获取文件内容
std::string getFileContent(std::string& uri)
{
// 当前uri中即为用户需要的文件,使用文件流打开文件
std::fstream f(uri);
// 如果文件为空,直接返回空字符串
if(!f.is_open())
return std::string();
// 否则就读取文件内容
std::string content;
std::string line;
while (std::getline(f, line))
content += line;
f.close();
return content;
}
|
接着,在创建一个函数用于处理获取URI以及构建文件内容,前面提到可以使用HttpResponse对象获取到对应的URI,所以当前函数需要接收一个HttpRequest对象,并且在HttpRequest类中需要提供获取URI的函数:
现在已经解决了文件问题,也就是说现在可以根据文件是否存在决定状态码的值和描述,根据前面的思路可以得出文件存在会返回空字符串,那么此时就说明状态码应该是404,否则就是200,所以这里就可以通过是否为空设置对应的状态码,而状态码描述可以通过状态码进行匹配,例如:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 根据状态码得到状态码描述
std::string setStatusCodeDesc(int status_code)
{
switch (status_code)
{
case 200:
return "OK";
case 404:
return "Not Found";
default:
break;
}
return std::string();
}
|
接下来继续完善构建函数buildHttpResponse,因为要设置状态码和状态码描述,所以需要两个成员接收这两个值,便于后面构建HTTP响应结构:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | void buildHttpResponse(HttpRequest &req)
{
// 获取uri
std::string req_uri = req.getReqUri();
// 根据uri获取文件内容
std::string content = getFileContent(req_uri);
if (content.empty())
{
// 如果为真,说明文件不存在
// 设置状态码为404并设置状态码描述
_status_code = 404;
_status_code_desc = setStatusCodeDesc(_status_code);
}
else
{
// 文件存在
_status_code = 200;
_status_code_desc = setStatusCodeDesc(_status_code);
}
}
|
处理完状态码和状态码描述之后,接下来就是将HTTP版本、状态码和状态码描述构建出一个HTTP响应行,首先修改原有的构造函数,删除不需要的字段:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | // 默认HTTP版本
const std::string default_http_ver = "HTTP/1.1";
class HttpResponse
{
public:
HttpResponse()
: _http_ver(default_http_ver)
{
}
private:
std::string _http_ver; // HTTP版本
// ...
};
|
接着,在buildHttpResponse函数中添加构建请求行的逻辑:
| C++ |
|---|
| void buildHttpResponse(HttpRequest &req)
{
// ...
// 构建响应行
_resp_line = _http_ver + " " + std::to_string(_status_code) + " " + _status_code_desc;
}
|
处理响应行
根据前面的要求「允许外部添加响应报头中的属性」,需要提供一个哈希表存储key和value,所以首先需要创建一个类成员,接着添加一个函数用于执行添加逻辑:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | class HttpResponse
{
public:
// ...
void insertRespHead(const std::string& key, const std::string& value)
{
_kv[key] = value;
}
// ...
private:
// ...
std::unordered_map<std::string, std::string> _kv;
// ...
};
|
接着,修改序列化中对响应行的序列化:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | // 序列化
bool serialize(std::string &out_str)
{
// ...
// 给响应报头的每一个字段加上\r\n
std::for_each(_kv.begin(), _kv.end(), [&](std::pair<std::string, std::string> p){
std::string temp = p.first + default_head_sep + p.second + default_sep;
out_str += temp;
});
// ...
return true;
}
|
处理响应体
根据客户端请求的内容读取服务端存在的对应文件并返回给客户端,没有时返回404页面,所以只需要在buildHttpResponse中根据是否有文件内容给定具体文件即可,对于存在对应的文件的,因为getFileContent返回的就是读取到的文件内容,所以直接将结果给响应头即可,但是对于404页面,并没有读取到一个实际的文件内容,这里可以考虑直接给getFileContent写入一个固定文件,即404文件,这样该函数获取到的文件内容就是404文件
有了基本思路,现在就是缺少这类文件。在添加文件之前,先仔细了解一下不带参数的URI,在介绍HTTP协议基本结构与基本实现HTTPServer中提到了/开始不一定是系统根目录,而是Web应用根目录,这个Web应用根目录实际上就是当前服务器程序所在目录下的一个文件夹,这个文件夹下放着一些静态资源,例如HTML、图片、视频、CSS、JavaScript等,所以客户端想访问资源本质就是让服务器在这个文件夹中找到对应的文件并将其中的内容返回给客户端
有了上面的概念,下面就是在当前服务器程序所在的目录创建一个Web应用根目录,基本目录结构如下:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | 主程序目录
- Web应用根目录
- src
- HTML文件
- assets
- stylesheets
- CSS文件
- JavaScripts
- JavaScript文件
- public
- images
- 图片文件
- videos
- 视频文件
- HttpServer程序
|
上面的目录只是一个参考目录,并不是固定的,可以根据自己或者其他地方的规定进行调整,下面将以这个目录结构为例演示,当前创建的目录结构如下:
| Text Only |
|---|
| HttpServer
- wwwroot
- src
- assets
- js
- style
- public
- images
- videos
- HttpServer_main
|
接着,为了演示出客户端正常接收到服务器存在的文件以及404文件,需要在src目录下创建两个HTML文件
网页文件
| HTML |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198 | <!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>商城</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Microsoft YaHei', sans-serif;
}
body {
background-color: #f5f5f5;
}
/* 头部样式 */
header {
background-color: #FF4500;
padding: 10px 0;
color: white;
}
.container {
width: 90%;
max-width: 1200px;
margin: 0 auto;
}
.header-top {
display: flex;
justify-content: space-between;
align-items: center;
padding-bottom: 10px;
}
.logo {
font-size: 24px;
font-weight: bold;
}
.search-box {
flex-grow: 1;
margin: 0 20px;
position: relative;
}
.search-box input {
width: 100%;
padding: 10px;
border: none;
border-radius: 4px;
outline: none;
}
.search-box button {
position: absolute;
right: 0;
top: 0;
height: 100%;
padding: 0 15px;
background-color: #ff6a00;
border: none;
color: white;
border-radius: 0 4px 4px 0;
cursor: pointer;
}
.user-actions a {
margin-left: 15px;
color: white;
text-decoration: none;
}
/* 导航栏样式 */
.main-nav {
background-color: #e43c00;
padding: 10px 0;
}
.main-nav ul {
display: flex;
list-style-type: none;
}
.main-nav li {
margin-right: 20px;
}
.main-nav a {
color: white;
text-decoration: none;
}
/* 产品区域样式 */
.section-title {
margin: 30px 0 15px;
padding-bottom: 10px;
border-bottom: 1px solid #ddd;
}
.product-grid {
display: grid;
grid-template-columns: repeat(auto-fill, minmax(240px, 1fr));
gap: 20px;
}
.product-card {
background-color: white;
border-radius: 5px;
padding: 15px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
transition: transform 0.3s;
}
.product-card:hover {
transform: translateY(-5px);
}
.product-img {
height: 180px;
background-color: #f0f0f0;
margin-bottom: 10px;
display: flex;
justify-content: center;
align-items: center;
color: #999;
}
.product-title {
font-weight: bold;
margin-bottom: 5px;
}
.product-price {
color: #ff4500;
font-weight: bold;
}
.price-original {
color: #999;
font-size: 0.9em;
text-decoration: line-through;
margin-left: 5px;
}
</style>
</head>
<body>
<header>
<div class="container">
<div class="header-top">
<div class="logo">优选商城</div>
<div class="search-box">
<input type="text" placeholder="搜索商品">
<button>搜索</button>
</div>
<div class="user-actions">
<a href="#">登录</a>
<a href="#">注册</a>
<a href="#">购物车</a>
<a href="#">我的订单</a>
</div>
</div>
</div>
</header>
<div class="container">
<h2 class="section-title">热卖推荐</h2>
<div class="product-grid">
<div class="product-card">
<div class="product-img">商品图片1</div>
<div class="product-title">超薄笔记本电脑</div>
<div class="product-price">¥4999 <span class="price-original">¥5999</span></div>
</div>
<div class="product-card">
<div class="product-img">商品图片2</div>
<div class="product-title">智能手机旗舰版</div>
<div class="product-price">¥3999 <span class="price-original">¥4599</span></div>
</div>
<div class="product-card">
<div class="product-img">商品图片3</div>
<div class="product-title">无线蓝牙耳机</div>
<div class="product-price">¥299 <span class="price-original">¥399</span></div>
</div>
<div class="product-card">
<div class="product-img">商品图片4</div>
<div class="product-title">智能手表</div>
<div class="product-price">¥899 <span class="price-original">¥1099</span></div>
</div>
</div>
</div>
</body>
</html>
|
| HTML |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221 | <!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>页面未找到 - 商城</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Microsoft YaHei', sans-serif;
}
body {
background-color: #f5f5f5;
}
/* 头部样式 */
header {
background-color: #FF4500;
padding: 10px 0;
color: white;
}
.container {
width: 90%;
max-width: 1200px;
margin: 0 auto;
}
.header-top {
display: flex;
justify-content: space-between;
align-items: center;
padding-bottom: 10px;
}
.logo {
font-size: 24px;
font-weight: bold;
}
.search-box {
flex-grow: 1;
margin: 0 20px;
position: relative;
}
.search-box input {
width: 100%;
padding: 10px;
border: none;
border-radius: 4px;
outline: none;
}
.search-box button {
position: absolute;
right: 0;
top: 0;
height: 100%;
padding: 0 15px;
background-color: #ff6a00;
border: none;
color: white;
border-radius: 0 4px 4px 0;
cursor: pointer;
}
.user-actions a {
margin-left: 15px;
color: white;
text-decoration: none;
}
/* 404页面特殊样式 */
.error-container {
text-align: center;
padding: 60px 20px;
}
.error-code {
font-size: 120px;
font-weight: bold;
color: #FF4500;
margin-bottom: 20px;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.1);
}
.error-message {
font-size: 24px;
color: #333;
margin-bottom: 30px;
}
.error-description {
font-size: 16px;
color: #666;
max-width: 600px;
margin: 0 auto 40px;
line-height: 1.6;
}
.error-image {
width: 300px;
height: 200px;
margin: 0 auto 30px;
display: flex;
align-items: center;
justify-content: center;
background-color: #f0f0f0;
border-radius: 10px;
color: #999;
}
.back-home {
display: inline-block;
background-color: #FF4500;
color: white;
padding: 12px 30px;
border-radius: 5px;
text-decoration: none;
font-weight: bold;
margin-top: 20px;
transition: background-color 0.3s;
}
.back-home:hover {
background-color: #e43c00;
}
.product-grid {
display: grid;
grid-template-columns: repeat(auto-fill, minmax(240px, 1fr));
gap: 20px;
}
.product-card {
background-color: white;
border-radius: 5px;
padding: 15px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
transition: transform 0.3s;
}
.product-card:hover {
transform: translateY(-5px);
}
.product-img {
height: 180px;
background-color: #f0f0f0;
margin-bottom: 10px;
display: flex;
justify-content: center;
align-items: center;
color: #999;
}
.product-title {
font-weight: bold;
margin-bottom: 5px;
}
.product-price {
color: #ff4500;
font-weight: bold;
}
.price-original {
color: #999;
font-size: 0.9em;
text-decoration: line-through;
margin-left: 5px;
}
</style>
</head>
<body>
<header>
<div class="container">
<div class="header-top">
<div class="logo">优选商城</div>
<div class="search-box">
<input type="text" placeholder="搜索商品">
<button>搜索</button>
</div>
<div class="user-actions">
<a href="#">登录</a>
<a href="#">注册</a>
<a href="#">购物车</a>
<a href="#">我的订单</a>
</div>
</div>
</div>
</header>
<div class="container">
<div class="error-container">
<div class="error-code">404</div>
<div class="error-image">
<svg width="150" height="150" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg">
<path d="M12 8V12L15 15" stroke="#FF4500" stroke-width="2" stroke-linecap="round" />
<circle cx="12" cy="12" r="9" stroke="#FF4500" stroke-width="2" />
<path d="M3 12H4M20 12H21M12 3V4M12 20V21" stroke="#FF4500" stroke-width="2"
stroke-linecap="round" />
</svg>
</div>
<h1 class="error-message">哎呀!页面走丢了</h1>
<p class="error-description">
您访问的页面可能已被移除、名称已更改或暂时不可用。
请检查您输入的网址是否正确,或者通过以下方式继续购物。
</p>
<a href="index.html" class="back-home">返回首页</a>
</div>
</div>
</body>
</html>
|
接着,修改buildHttpResponse逻辑,确保可以读取到文件并将文件内容存储到响应体中:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | // 404页面固定路径
std::string default_404_page = "wwwroot/src/404.html";
void buildHttpResponse(HttpRequest &req)
{
// 获取uri
std::string req_uri = req.getReqUri();
// 根据uri获取文件内容
std::string content = getFileContent(req_uri);
if (content.empty())
{
// 如果为真,说明文件不存在
// 设置状态码为404并设置状态码描述
_status_code = 404;
_status_code_desc = setStatusCodeDesc(_status_code);
// 读取404页面并设置响应体
_resp_body = getFileContent(default_404_page);
}
else
{
// 文件存在
_status_code = 200;
_status_code_desc = setStatusCodeDesc(_status_code);
// 设置响应体
_resp_body = content;
}
// 构建响应行
_resp_line = _http_ver + " " + std::to_string(_status_code) + " " + _status_code_desc;
}
|
修改HttpServer类
因为HttpServer需要调用sendData函数,该函数需要传入一个字符串作为发送数据,而HTTP响应中存在一个序列化函数,可以调用这个函数可以传入一个字符串,并将序列化后的字符串存储到参数的字符串中,这样就可以实现发送。所以整体handleHttpRequest逻辑修改如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | void handleHttpRequest(SockAddrIn sock_addr_in, int ac_socketfd)
{
// ...
// 构建HTTP响应
HttpResponse resq;
resq.buildHttpResponse(req);
// 序列化
std::string out_str;
resq.serialize(out_str);
// 发送给客户端
bs->sendData(out_str, ac_socketfd);
}
|
测试
主函数与上一节一样,测试结果如下:
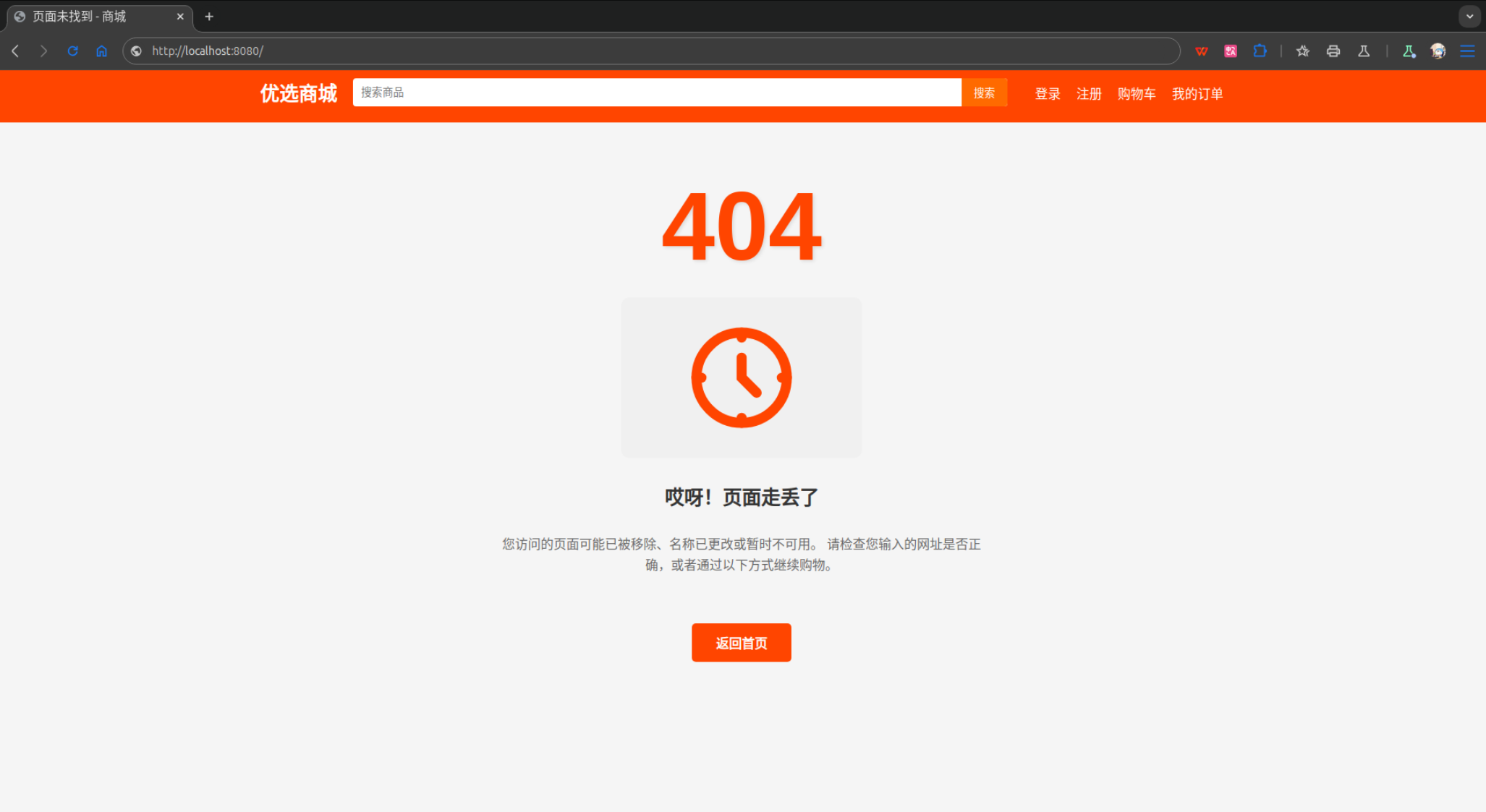
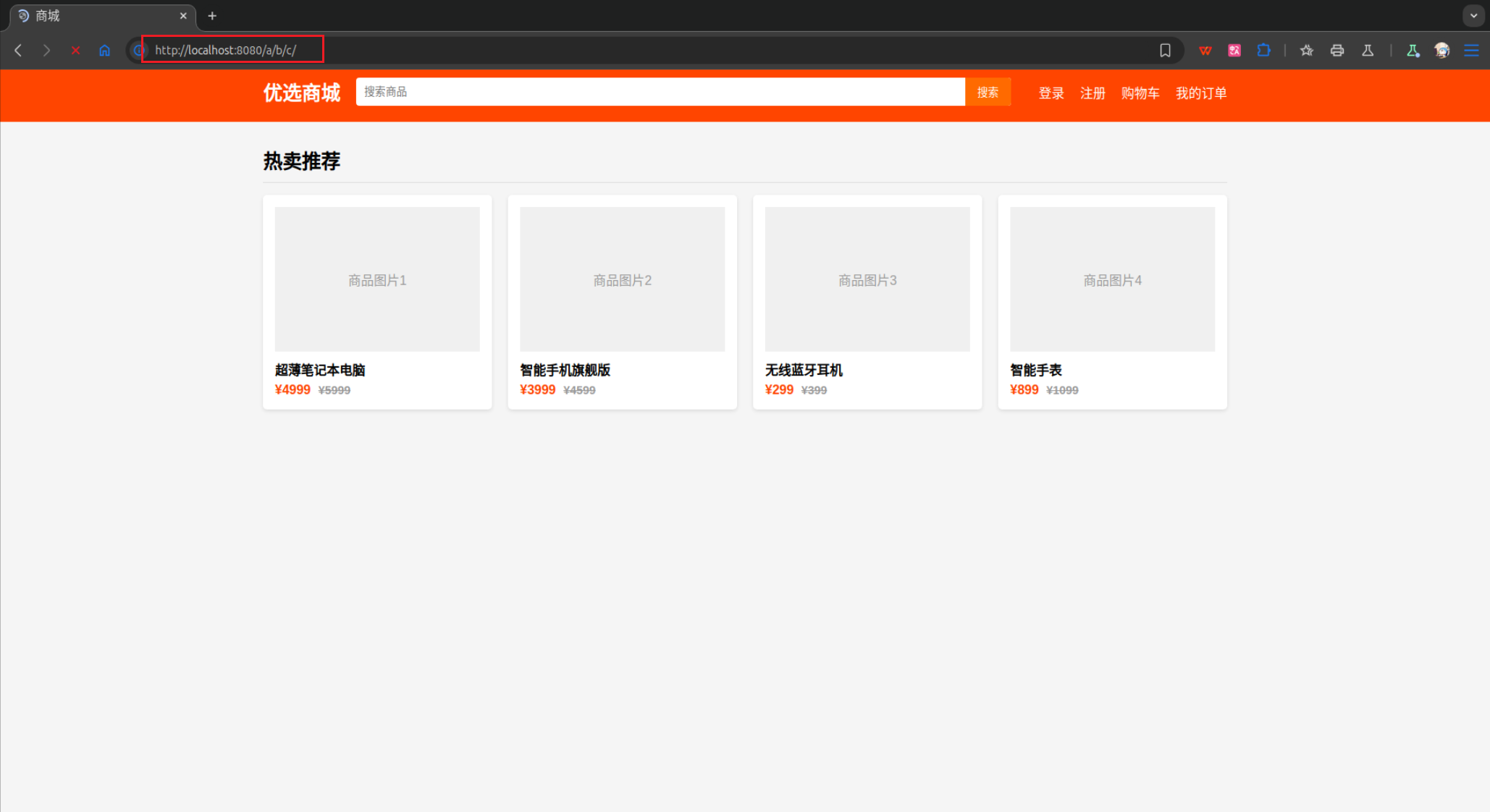
从上面的测试结果可以发现,的确可以接收到数据,如果将地址栏的内容修改为localhost:8080/index.html,结果如下:
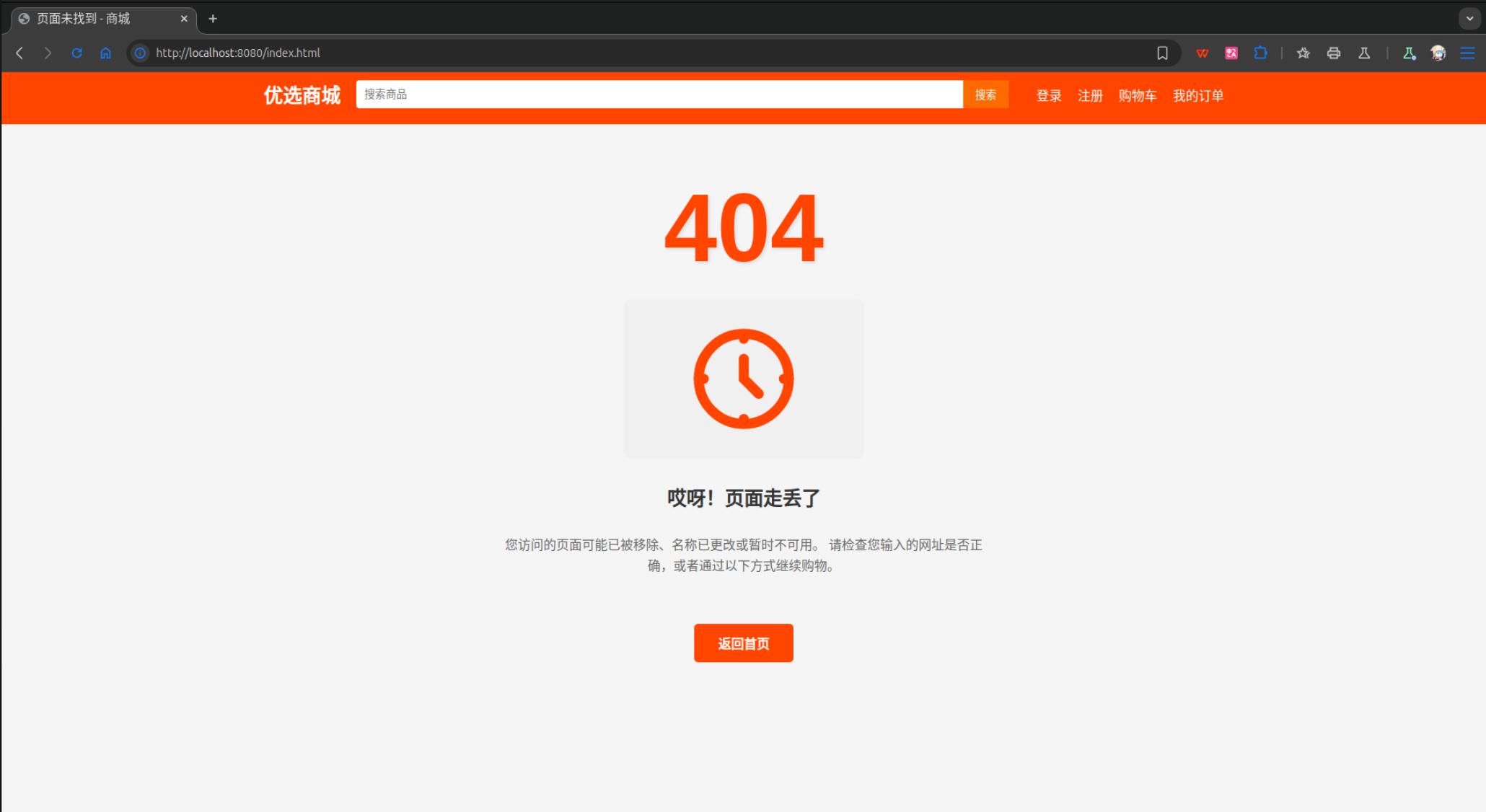
这个测试结果并不是像预期的那样显示主页的内容,而是显示404页面。那么明明存在index.html文件,为什么会出现无法读取到index.html?这是因为在解析URI时并没有考虑到URI起始的/,实际上getFileContent函数得到的uri字符串内容是/index.html,而已有的index.html文件路径为wwwroot/src/index.html,所以还需要在已有的uri上还需要加入默认的Web应用目录wwwroot/src,修改如下:
| C++ |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | // Web应用路径
std::string default_webapp_dir = "wwwroot/";
// HTML文件路径
std::string default_html_dir = "src";
// 404页面固定路径
std::string default_404_page = default_webapp_dir + default_html_dir + "/404.html";
void buildHttpResponse(HttpRequest &req)
{
// 获取uri
// ...
// 补充uri
std::string real_uri = default_webapp_dir + default_html_dir + req_uri;
// 根据uri获取文件内容
std::string content = getFileContent(real_uri);
// ...
}
|
再次测试,结果如下:
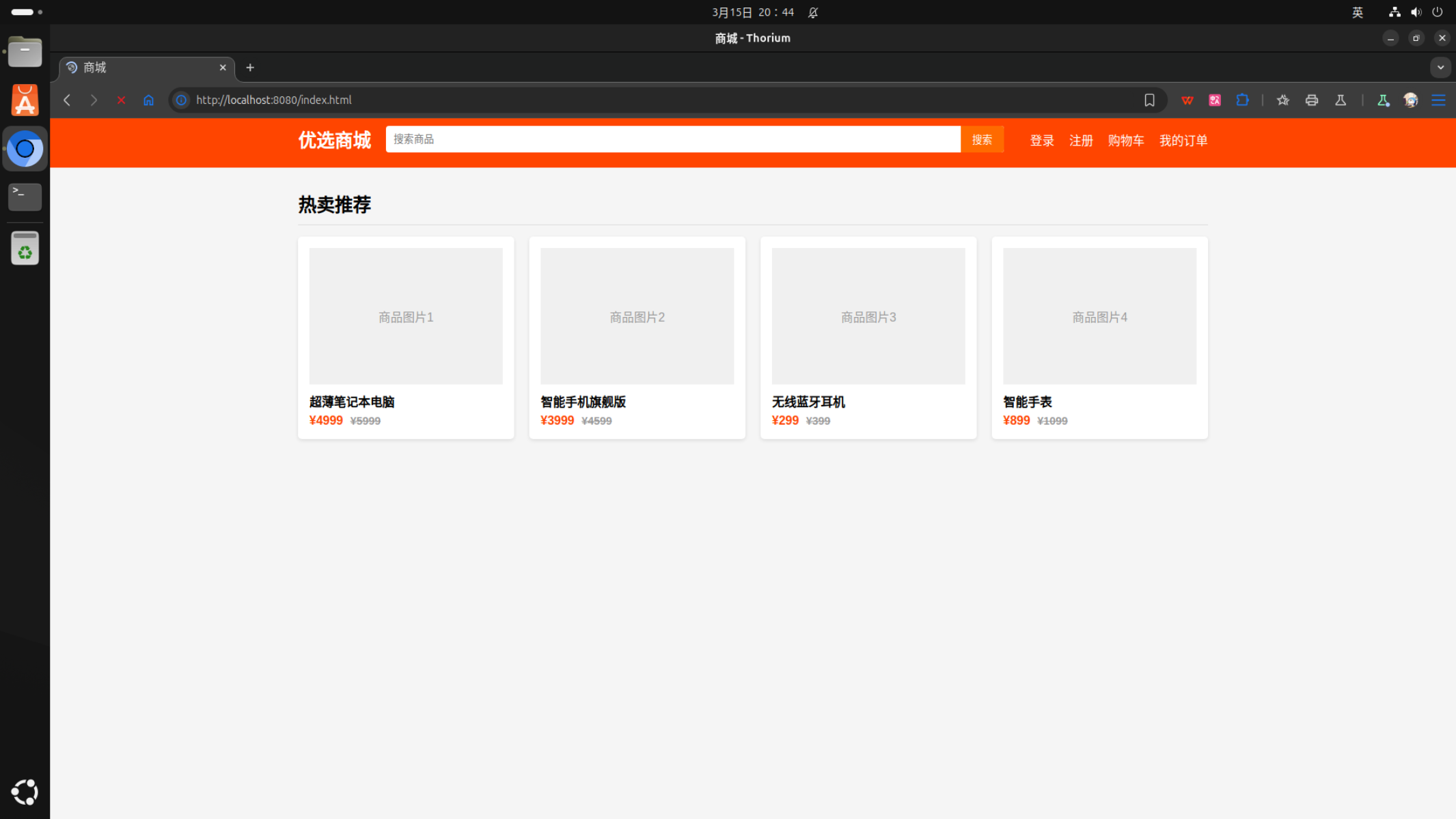
优化
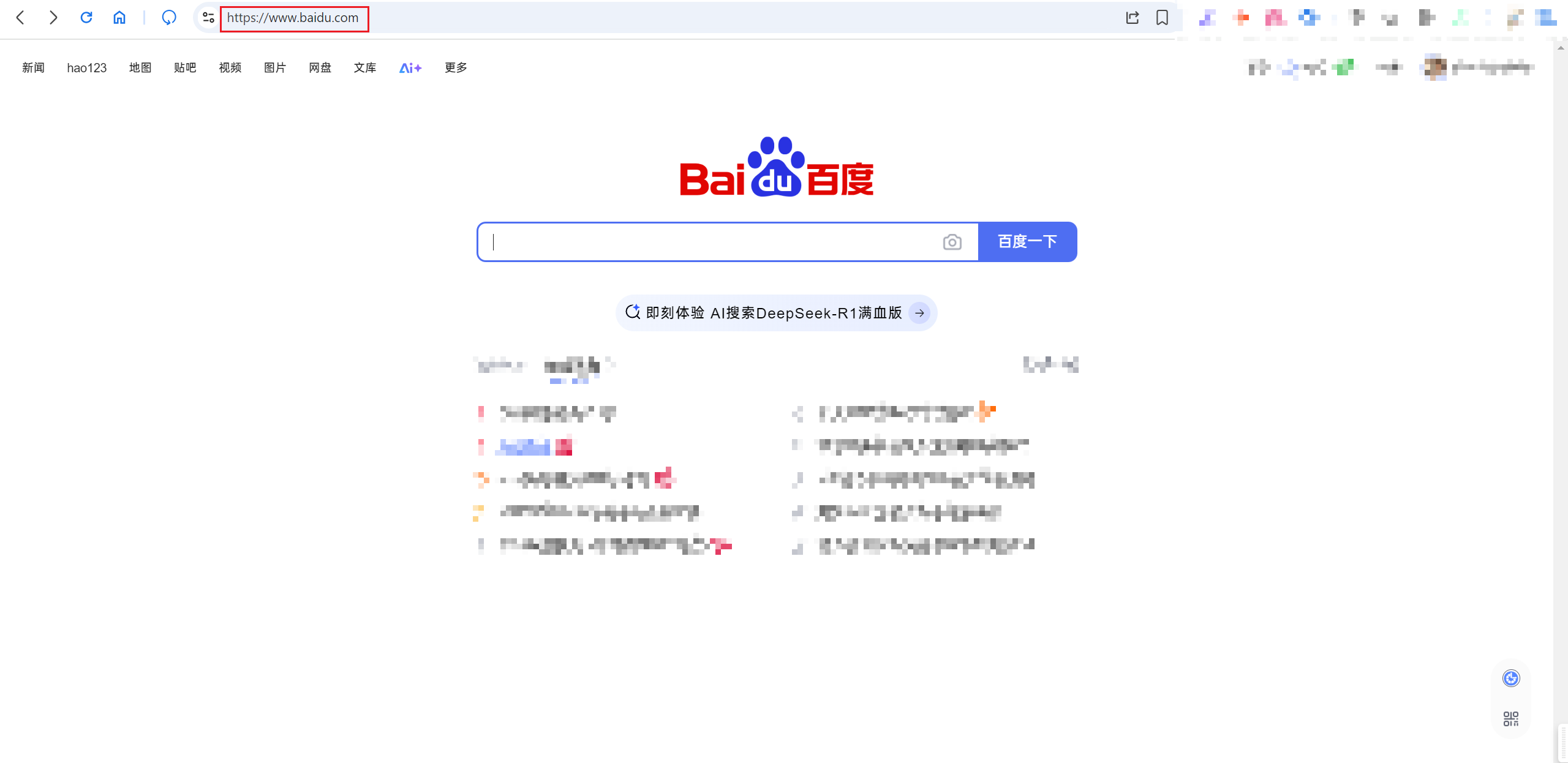
从上面的测试可以发现,如果想要访问index.html文件还需要手动加上/index.html,但是访问一个实际的网站时,尽管没有携带/index.html,依旧可以访问到网站的index.html文件,例如访问百度的首页:
默认访问:
在网址后添加/index.html:
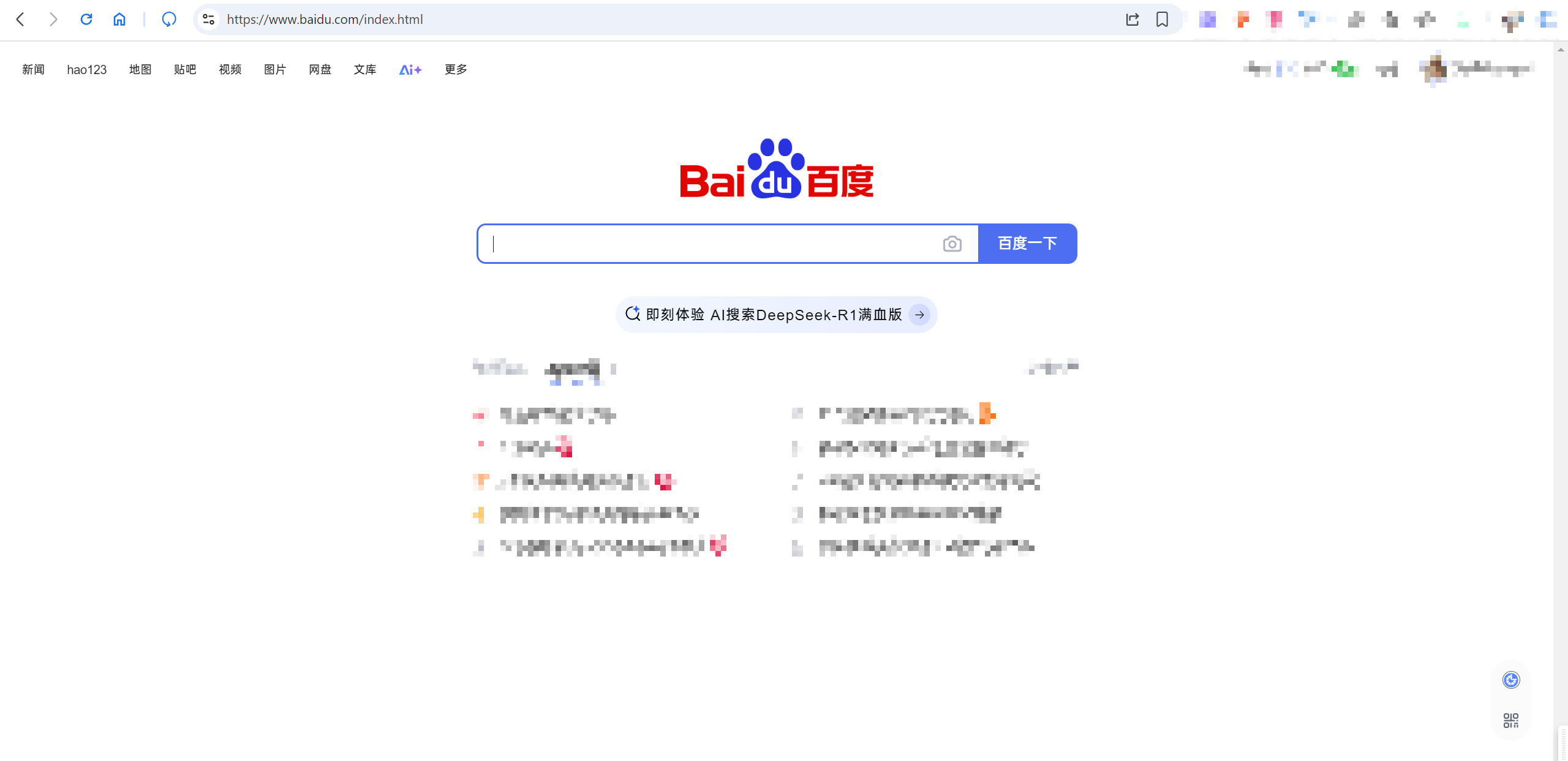
因为直接输入网址,浏览器请求的默认就是Web应用根目录下的某一个文件,只是默认情况下隐藏了IP地址+端口号后的/,实现这个效果的方式很简单,只需要在getFileContent函数的开始判断是否是/,如果是就直接返回index.html的内容即可。思路的确如此,但是在上面先处理了传递给getFileContent的参数为添加了wwwroot/src的字符串,所以实际上如果只有一个/,那么传递给getFileContent函数的参数为wwwroot/src/,所以修改如下:
| C++ |
|---|
| // 获取文件内容
std::string getFileContent(std::string &uri)
{
// 默认访问index.html文件
if(uri == "wwwroot/src/")
uri = "wwwroot/src/index.html";
// ...
}
|
再次测试,观察结果:

可以发现已经默认到了index.html的内容
虽然上面的思路的确可以实现问题,但是如果默认以/结尾,那么只要判断最后字符串是否是/即可,这样不论前面的内容是什么,只要是以/结尾,都可以访问到主页,所以还可以修改为:
| C++ |
|---|
| // 获取文件内容
std::string getFileContent(std::string &uri)
{
// 默认访问index.html文件
if(uri.back() == '/')
uri = "wwwroot/src/index.html";
// ...
}
|
现在,不论前面是什么都可以访问到index.html,哪怕是不存在的目录: