Linux进程基础¶
约 2476 个字 133 行代码 14 张图片 预计阅读时间 10 分钟
进程介绍¶
进程的本质是在计算机内存中运行的程序,但是这一个概念太过于广泛
要了解进程,首先采用前面在操作系统基础中介绍的思想「先描述,再组织」,每一个进程本质也是一个结构(一般称为PCB(Process Control Block,进程控制块),在Linux下的PCB称为task_struct),计算机将程序加载到内存,就会在内存中添加一个进程,那么此时就会形成一个结构体,该结构体中存在进程的一些描述,例如进程的在内存中的位置、进程的编号、对应数据和代码的地址等,在程序执行前,进程会被排列到一个数据结构,通过操作系统调度器从数据结构中取出进程就代表对应的进程获取到CPU的使用权,此时就会通过对应进程的结构体中的相关数据加载代码和数据进行运算、逻辑处理,从而到达执行程序的效果
这一过程可以看出,进程=程序代码和数据+进程结构体
进程可以粗略得分为两种:
- 执行完对应代码就退出
- 一直运行在后台,也被称为「常驻进程」
Linux下查看进程¶
首先,通过下面的C语言代码创建一个进程:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 | |
对应的Makefile代码如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
编译运行前面的C语言代码,并在Linux下查看对应进程
可以使用下面的方式:
| Bash | |
|---|---|
1 2 3 | |
上面的指令中的ps ajx代表查看当前系统运行时所有的进程以及部分信息,直接执行就可以看到进程信息
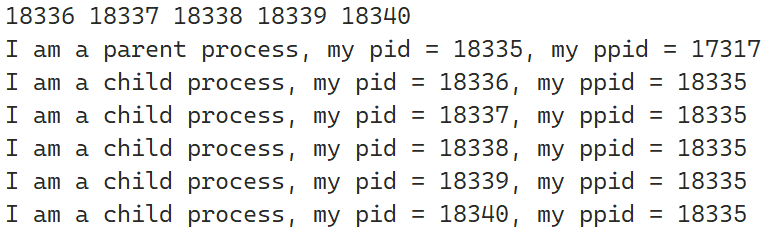
可以看到对应的进程为:

在Linux下实际上进程都被保存在一个名为proc的目录下,这个目录不是存在于磁盘中的目录,而是操作系统运行时进程出现创建的,使用下面的命令查看该目录:
| Bash | |
|---|---|
1 | |
Note
proc目录在根目录下,与home目录同级
在proc目录中,以数字为目录名的目录都是创建的进程,这些数字代表着每一个进程的PID
再次运行前面的C语言代码,使用下面的代码查看程序进程信息以及在proc目录下的位置

结束进程的方式¶
在Linux下,可以使用两种方式结束进程
- 快捷键 Ctrl+C
- 使用
kill指令:Kill -9 进程PID
fopen函数中何为「当前路径」¶
在前面使用C语言中的fopen函数以写入的方式打开文件时,如果指定的文件不存在,就会在「当前路径」下创建一个新同名文件,此时「当前路径」即为与源文件同级的路径下,之所以会出现这个情况就是因为在进程信息中,存在着cwd信息,该信息记录着程序源文件的位置,表示当前工作目录(current work directory)
运行前面的C语言程序,并查看/proc目录下对应该C语言程序的进程目录
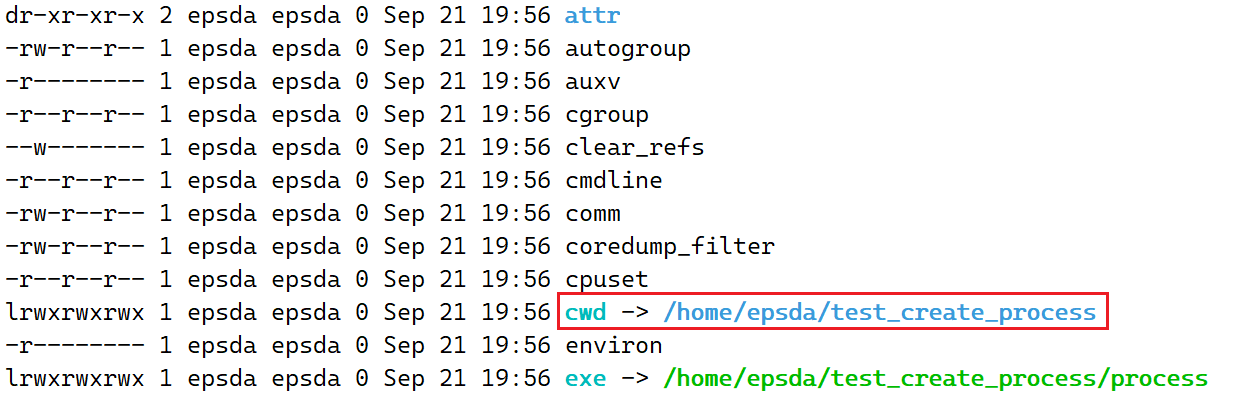
可以看到cwd指向着当前源文件所在的目录,如果此时在C语言程序中创建了一个文件,该文件就会保存到该目录下,这一个目录所在的路径也被称为「当前路径」
如果想修改这个路径,可以使用chdir函数修改为想要的路径,但是必须确保指定的路径对应的目录具有写权限,chdir函数原型如下:
| C | |
|---|---|
1 | |
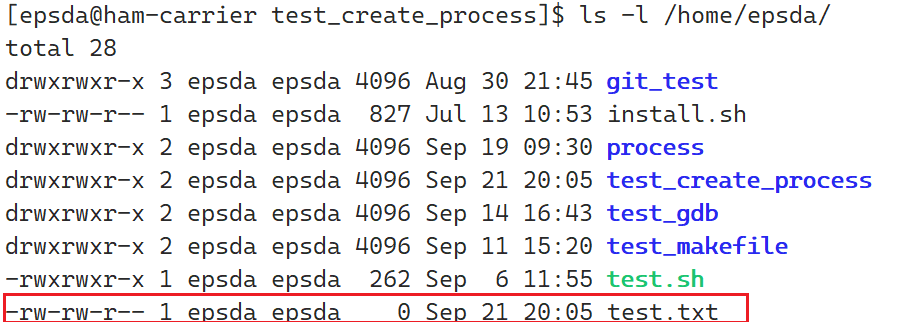
修改前面的C语言代码,将指定路径更改为当前路径的父路径/home/epsda下,并以写的方式在该路径下创建一个名为test.txt的文件
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
此时就会在/home/epsda创建一个名为test.txt的文件,如下图:
进程对应程序文件位置¶
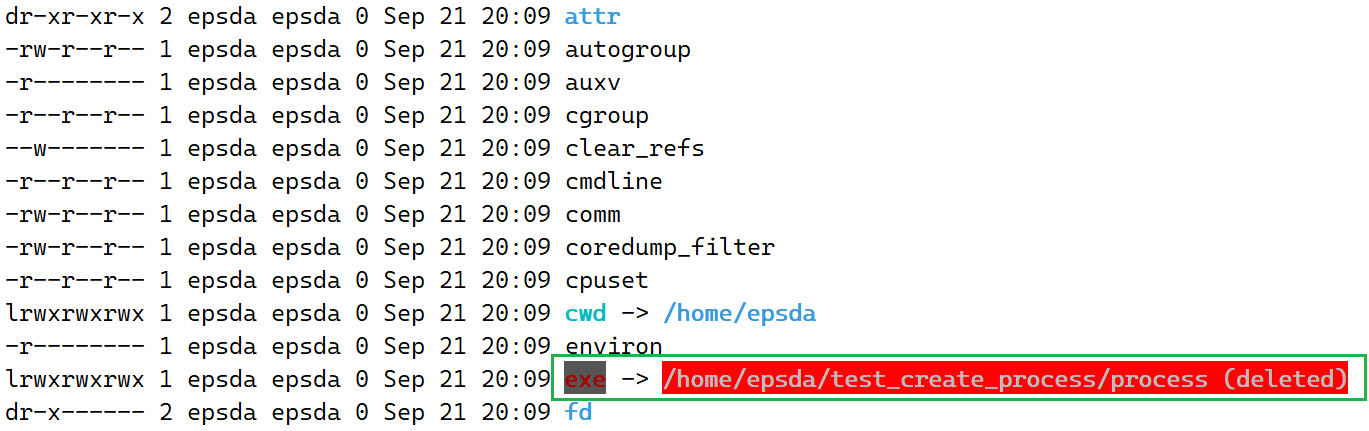
在前面C语言程序对应的进程目录中除了可以看到cwd以外,还可以看到一个名为exe的软链接,该链接指向着一个路径,如下:
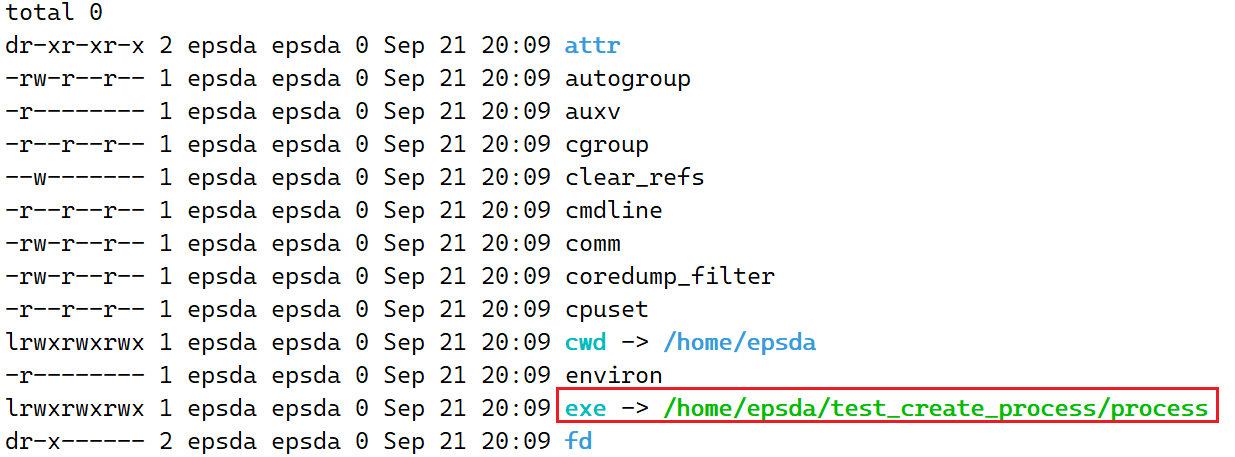
该路径对应的即为加载到内存中的代码和数据(进程组成的一部分),如果在运行时将该路径下的process文件删除,此时已经运行的进程不会受到影响,因为对应的代码和数据已经加载进内存,受影响的只是下一次无法直接使用运行程序的方式创建进程
删除后再次查看结果如下:
进程PID与PPID¶
PID是Linux系统下每一个进程对应的一个编号,该编号会因为进程产生的时间不同而不同,例如每一次运行前面的C语言代码都会得到一个不同的PID
如果想获取到当前进程的PID,可以使用getpid()函数,该函数原型如下:
| C | |
|---|---|
1 | |
其中pid_t类似于long类型,是一个长整型,该函数不需要传递形参
在前面的C语言代码中添加该函数并打印该进程的PID,对比使用指令查看进程信息下的PID
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |


可以看到PID一致
Note
一般连续创建的进程,PID会是连续的
PID是进程的编号,PPID是指定进程的父进程的编号,当前进程也被称为对应父进程的子进程
同样,在代码中想获取到当前进程的父进程对应的PPID,可以使用getppid()函数,原型如下:
| C | |
|---|---|
1 | |
对前面C语言的代码进行修改,如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
多次运行代码后结果如下:

可以发现,每一次运行代码,PID都会改变,但是PPID始终不变,因为其父进程始终是同一个进程,通过查看进程的指令可以找到PID为14901对应的父进程:

bash是Linux下的指令解释器,每一次执行指令时,实际上就是将对应的指令交给了bash,由bash再交给操作系统进行执行,当执行上面程序的进程时,实际上是创建了一个bash的子进程,再由子进程执行对应的程序代码和数据
创建子进程fork¶
简单了解fork函数¶
fork函数原型如下:
| C | |
|---|---|
1 | |
在Linux编程手册中对fork的解释如下:

对应的函数返回值的解释如下:
| Text Only | |
|---|---|
1 2 | |
大意为:成功的情况下,该函数返回子进程的PID给父进程,返回0给子进程。失败的情况下,该函数返回-1给父进程,不创建任何子进程,并恰当设置错误代码
简单使用fork函数¶
根据前面对fork函数的介绍,修改前面的C语言代码如下:
| C | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
运行结果如下:

可以看到,子进程的PPID即为父进程PID,与前面的思想对应
简单了解fork细节¶
上面的代码中一共存在着三个待解决的问题:
- 使用
fork创建子进程,为什么可以通过if和else...if区分子进程和父进程 - 为什么
fork函数出现了两个返回值 - 为什么两个分支语句
if和else...if都执行了
对于第一个问题来说,根据fork函数的返回值描述,当函数运行成功的情况下,会返回子进程的PID给父进程,PID一般都是大于0的,而子进程会收到fork函数的返回值为0,所以当上面代码中的id变量大于0时,就会走if语句,而唯一一个接收到的id大于0的就是父进程;同理,子进程的id变量等于0,就会走else...if语句。
对于第二个问题来说,实际上执行fork函数时,在返回pid之前就已经执行完了创建子进程逻辑,此时父进程和子进程共享代码,但是各自独立数据,父进程拥有自己的返回值,子进程也拥有自己的返回值,所以此时return的时候是每个进程返回各自的返回值
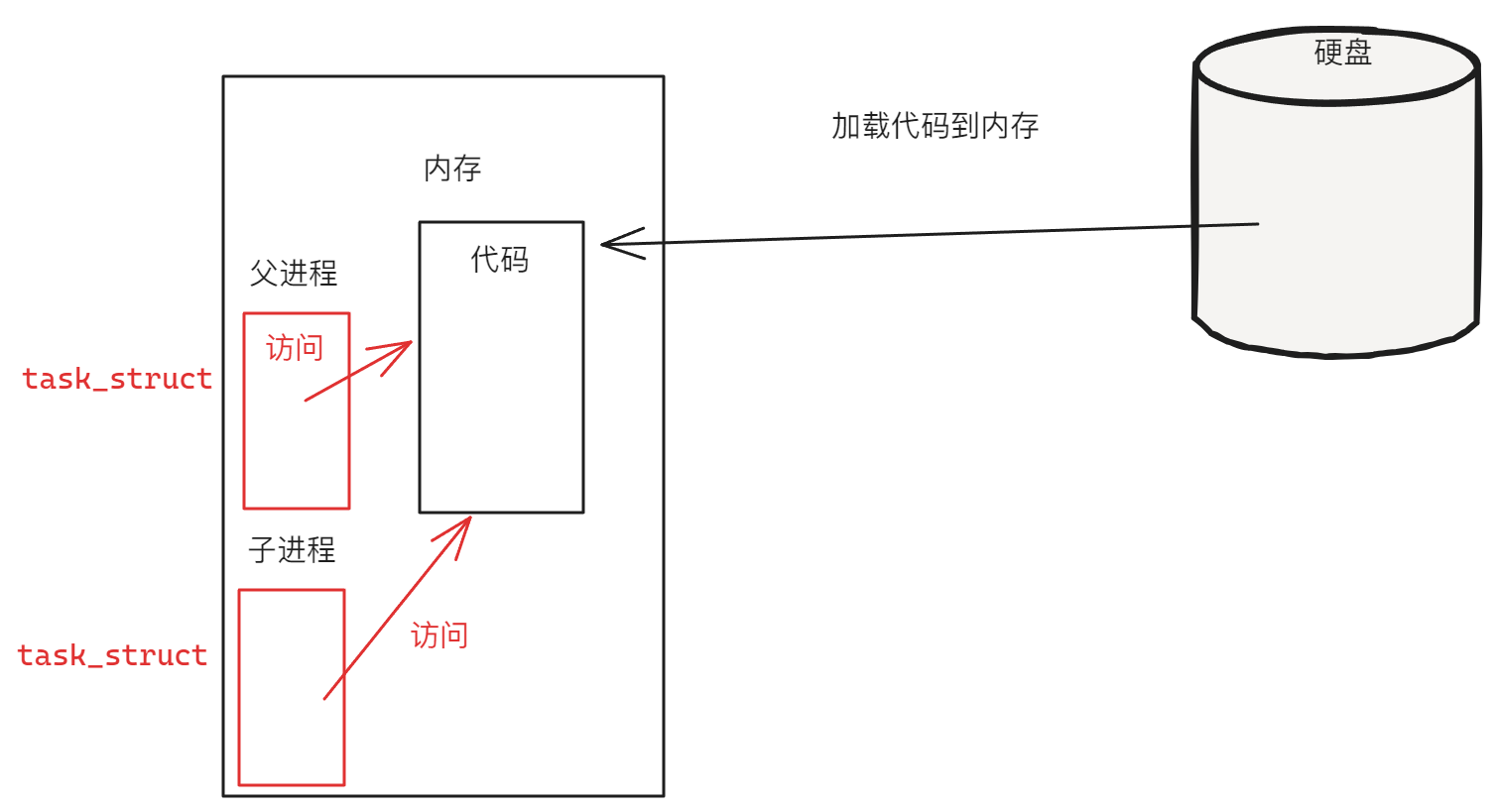
对于第三个问题来说,当代码执行到fork函数时,会执行fork函数的内部逻辑,再执行完其主逻辑代码后,就已经创建出了子进程(对应存在一个子进程的task_struct),此时子进程会与父进程共享同一块代码,但是子进程拥有自己的数据,并使用自己的数据执行代码。而之所以需要共享同一块代码,是因为父进程的代码是从硬盘中加载的,但是子进程的代码并不存在与硬盘,从而也就无法加载,而之所以不同的进程有着不同的数据,这是进程独立性的主要体现,可以用下图先简单理解这个过程,具体过程会在进程地址空间讲解:
Note
此处,子进程的task_struct实际上先是对父进程的task_struct的拷贝,再对其中的内容进行一定的修改
创建多个子进程(初探)¶
前面创建进程只是创建了一个子进程,实际上,在Linux下可以创建多个子进程,但是多个子进程只能有一个共同的父亲,所以在Linux下,进程体系结构类似于二叉树
使用下面的C++代码创建一个子进程,并将子进程的PID存入vector对象中
| C++ | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
对应的Makefile如下:
| Makefile | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
运行结果如下: